摆烂了挺久,零零散散的终于完成数据结构与算法的部分内容学习,不过感觉这玩意仿佛就学习的那一段时间记得比较
清楚,过段时间就忘了干净了,还是比较难消化的。抛开学习上的事情以外,因为这疫情的持续影响最近感觉挺多事情
都不太顺利,无论是求职还是生活的各方面,自己正如11、12月寒冬中熄灭的火种一般,也许这就是所谓的时代的一粒
沙,落在每个人肩头都是一座大山,唉。
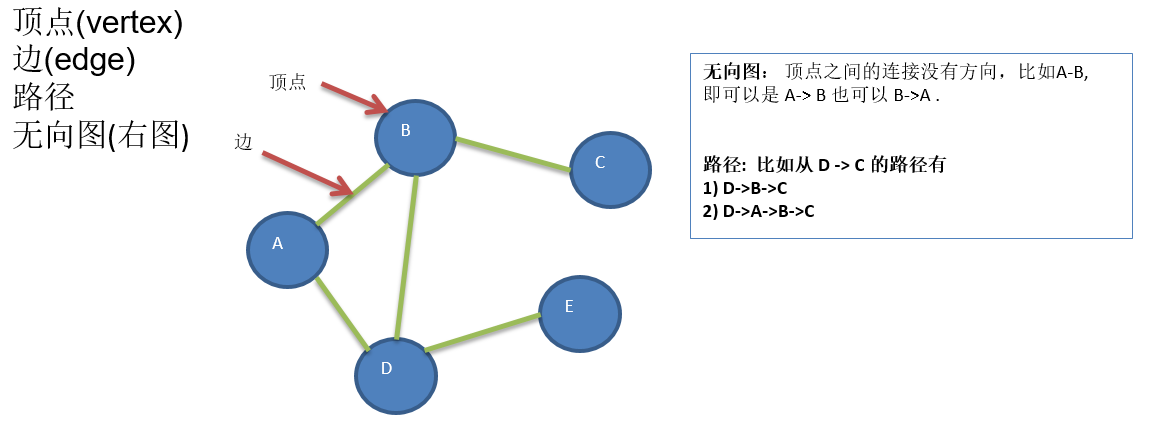
数据结构 1.线性结构
特点:数据元素之间存在一对一的线性关系
有两种存储结构:
顺序存储结构
顺序存储的线性表称为顺序表,其中存储的元素的内存空间都是连续的
链式存储结构
链式存储的线性表称为链表,其中的存储元素的内存空间不一定是连续的,元素节点中存放数据元素以及相邻元素的地址信息
线性结构常见的有:数组、队列、链表和栈
2.非线性结构
非线性结构有:二维数组、多维数组、广义表、树结构、图结构
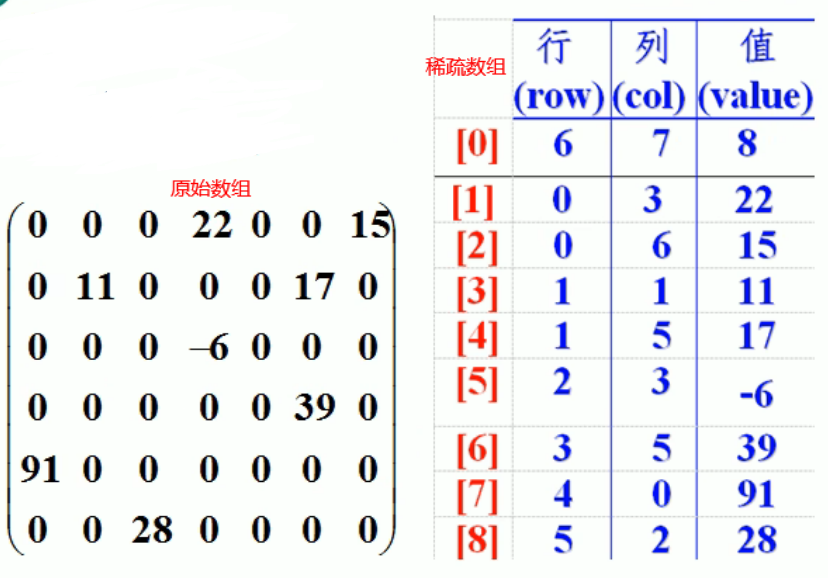
稀疏数组 定义:当一个数组内的大部分元素都为0,或都是同一个值时
处理方法:①记录数组总共几行几列,有多少个不同的值
②把不同值元素的行列值记录在一个小型数组中,从而缩小程序的规模
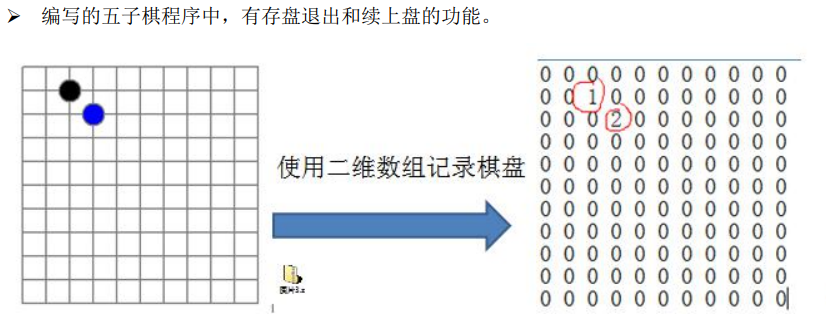
思路分析:二维数组 —> 稀疏数组 —> 转换为文件 (且可以逆转)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 public class SparseArray { public static void main (String[] args) { int [][] array = new int [11 ][11 ]; array[1 ][2 ] = 1 ; array[2 ][3 ] = 2 ; for (int i = 0 ; i < array.length; i++) { for (int j = 0 ; j < array[i].length; j++) { System.out.print(array[i][j] + "\t" ); } System.out.println(); } int sum = 0 ; for (int i = 0 ; i < array.length; i++) { for (int j = 0 ; j < array[i].length; j++) { if (array[i][j] != 0 ){ sum += 1 ; } } } System.out.println("========================" ); int [][] sparseArray = new int [sum+1 ][3 ]; sparseArray[0 ][0 ] = 11 ; sparseArray[0 ][1 ] = 11 ; sparseArray[0 ][2 ] = sum; int count = 0 ; for (int i = 0 ; i < array.length; i++) { for (int j = 0 ; j < array[i].length; j++) { if (array[i][j] != 0 ){ count++; sparseArray[count][0 ] = i; sparseArray[count][1 ] = j; sparseArray[count][2 ] = array[i][j]; } } } for (int i = 0 ; i < sparseArray.length; i++) { for (int j = 0 ; j < sparseArray[i].length; j++) { System.out.print(sparseArray[i][j] + "\t" ); } System.out.println(); } System.out.println("========================" ); int [][] theNewArray = new int [sparseArray[0 ][0 ]][sparseArray[0 ][1 ]]; for (int i = 1 ; i < sparseArray.length; i++) { theNewArray[sparseArray[i][0 ]][sparseArray[i][1 ]] = sparseArray[i][2 ]; } for (int i = 0 ; i < theNewArray.length; i++) { for (int j = 0 ; j < theNewArray[i].length; j++) { System.out.print(theNewArray[i][j] + "\t" ); } System.out.println(); } } }
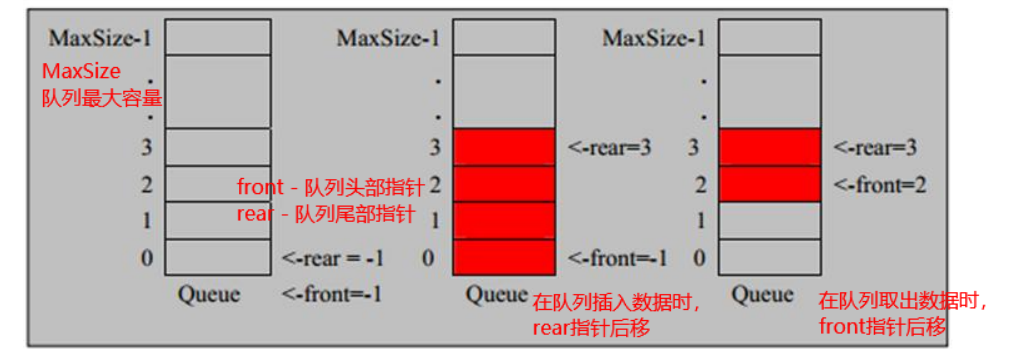
队列
特点:先进先出原则 队列的左端为队头,右端为队尾
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 public class QueueArray1 { private int front; private int rear; private int [] queueArray; private int maxSize; public QueueArray1 () { } public QueueArray1 (int maxSize) { this .front = -1 ; this .rear = -1 ; this .queueArray = new int [maxSize]; this .maxSize = maxSize; } public boolean queueIsFull () { return rear = = maxSize-1 ; } public boolean queueIsEmpty () { return front = = rear; } public void addDataInQueue (int num) { if (queueIsFull()){ throw new RuntimeException ("队列已满,无法添加数据" ); }else { rear++; queueArray[rear] = num; } } public int getDataFromQueue () { if (queueIsEmpty()){ throw new RuntimeException ("队列没有任何数据,获取失败" ); } front++; return queueArray[front]; } public void showQueue () { if (queueIsEmpty()){ throw new RuntimeException ("队列没有任何数据" ); }else { for (int i = 0 ; i < queueArray.length; i++) { System.out.print(queueArray[i] + "\t" ); if (i == queueArray.length - 1 ){ System.out.println(); } } } } public int showTheFirst () { if (queueIsEmpty()){ throw new RuntimeException ("队列为空" ); }else { return queueArray[front+1 ]; } } }
直接使用数组模拟队列存在一个问题:即当队列的所有数据取出后依然无法往队列中添加数据
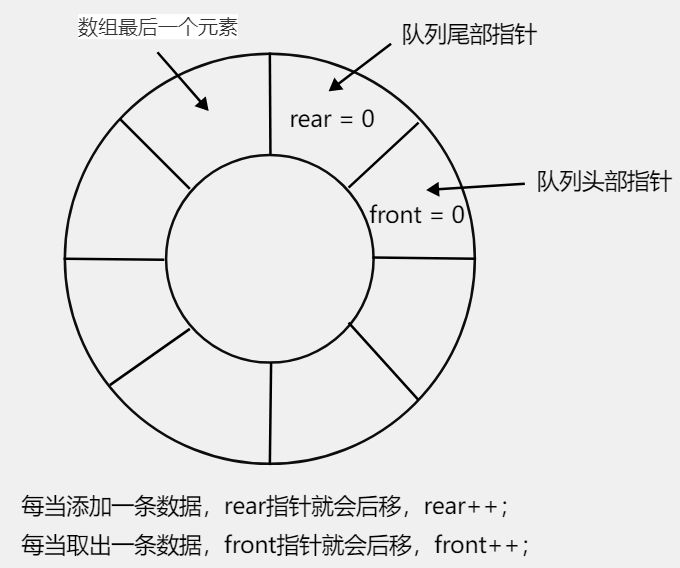
使用环形列表解决上述的问题,采用数组模拟环形队列(这个方法实际上是牺牲了一个存储单位,且最关键的部分就是取模思想
对数组进行修改
将font定义为指向队列中的第一个元素queueArray[front],其初始值为0;
将rear定义为指向数组最后一个元素的后一个位置,其初始值为0;
当队列为满时,即(rear + 1) % maxSize = front;
当队列已满的时候,rear指向的这个单元是没有数据的且占用数组最后一个索引,也就是实际上rear真正值是maxSize -1
即rear = maxSize - 1 ,当 rear + 1 = maxSize -1 +1;
在这个情况下相当于maxSize % maxSize;试问这个情况下 结果有不为0的情况吗?front = 0;
因此说明rear指针已经添加过一轮回到默认值的位置
还看不懂的话,参考这个文章 –> 点击这里
当队列为空时,rear == front;
在这种情况下,队列的有效数据是(rear + maxSize - front)% maxSize
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 public class QueueArray2 { private int front; private int rear; private int [] queueArray; private int maxSize; public QueueArray2 () { } public QueueArray2 (int maxSize) { this .front = 0 ; this .rear = 0 ; this .queueArray = new int [maxSize]; this .maxSize = maxSize; } public boolean queueIsFull () { return (rear + 1 ) % maxSize == front; } public boolean queueIsEmpty () { return front = = rear; } public int getFront () { return front; } public void addDataInQueue (int num) { if (queueIsFull()){ throw new RuntimeException ("队列已满,无法添加数据" ); }else { queueArray[rear] = num; rear = (rear + 1 ) % maxSize ; } } public int getDataFromQueue () { if (queueIsEmpty()){ throw new RuntimeException ("队列没有任何数据,获取失败" ); } int value = queueArray[front]; front = (front + 1 ) % maxSize; return value; } public void showQueue () { if (queueIsEmpty()){ throw new RuntimeException ("队列没有任何数据" ); }else { for (int i = front; i < front + queueSize() ; i++) { System.out.print("queue:" + queueArray[i % maxSize] + "\n" ); } } } public int queueSize () { return (rear + maxSize - front) % maxSize; } public int showTheFirst () { if (queueIsEmpty()){ throw new RuntimeException ("队列没有任何数据" ); }else { return queueArray[front]; } } }
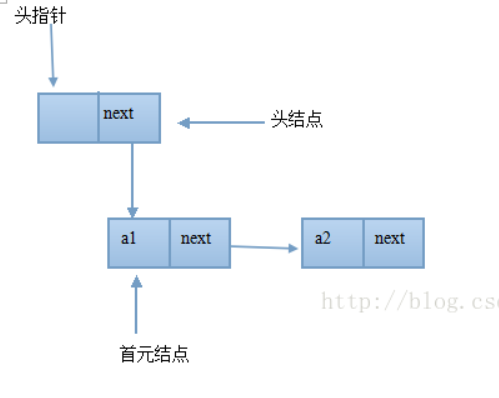
链表 链表的特点:
①链表是以节点的方式进行存储
②每个节点包含data域,next域(下一个节点的信息)
③链表中的各个节点在内存中不一定是连续存储的
④链表分为带头节点和不带头节点的链表
单向链表 单链表的缺点:只能单向查找;不能实现自我删除
(带头节点,不考虑插入节点的编号的情况下):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 class SingleLinkedList { private TestNode head = new TestNode (0 ,null ,null ); public void add (TestNode node) { TestNode temp = head; while (true ){ if (temp.nextNode == null ) { break ; } else { temp = temp.nextNode; } } temp.nextNode = node; } public void showLinkedList () { if (head.nextNode == null ){ System.out.println("当前链表为空" ); return ; } TestNode temp = head; while (true ){ if (temp.nextNode != null ){ System.out.println(temp.nextNode); temp = temp.nextNode; }else { break ; } } } } class TestNode { public int num; public String name; public String nickname; public TestNode nextNode; public TestNode () { } public TestNode (int num, String name, String nickname) { this .num = num; this .name = name; this .nickname = nickname; } }
(带头节点,考虑插入节点的编号的情况下):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 class SingleLinkedList2 { private TestNode2 head = new TestNode2 (0 ,null ,null ); public void delete (int node) { TestNode2 temp = head; while (true ){ if (temp.nextNode == null ){ System.out.println("链表为空" ); break ; } else if (temp.nextNode.num == node){ TestNode2 deletedNode = temp.nextNode; TestNode2 DeletedNextNode = deletedNode.nextNode; if (DeletedNextNode != null ){ temp.nextNode = DeletedNextNode; break ; }else { System.out.println("当前删除的是链表中最后一个节点" ); temp.nextNode = null ; break ; } } else { temp = temp.nextNode; if (temp.nextNode == null ){ System.out.println("指定删除的节点不存在" ); break ; } } } } public void update (TestNode node) { TestNode2 temp = head; while (true ){ if (temp.nextNode == null ){ System.out.println("链表为空" ); break ; }else if (temp.nextNode.num == node.num){ temp.nextNode.name =node.name; temp.nextNode.nickname =node.nickname; break ; }else { temp = temp.nextNode; } } } public void add (TestNode2 node) { TestNode2 temp = head; while (true ){ if (temp.nextNode == null ){ temp.nextNode = node; break ; } if (temp.nextNode.num == node.num){ System.out.println("当前添加的数据:" + node + ",已存在于链表中" ); break ; } int next = temp.nextNode.num; int now = node.num; if (now < next){ node.nextNode = temp.nextNode; temp.nextNode = node; break ; }else { temp = temp.nextNode; } } } public void showLinkedList () { if (head.nextNode == null ){ System.out.println("当前链表为空" ); return ; } TestNode2 temp = head; while (true ){ if (temp.nextNode != null ){ System.out.println(temp.nextNode); temp = temp.nextNode; }else { break ; } } } } class TestNode2 { public int num; public String name; public String nickname; public TestNode2 nextNode; public TestNode2 () { } public TestNode2 (int num, String name, String nickname) { this .num = num; this .name = name; this .nickname = nickname; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 public static void ReservePrintLinkedList (SingleLinkedList3 reservedList) { if (reservedList.head.nextNode == null ){ System.out.println("链表为空" ); return ; } Stack<TestNode3> stack = new Stack <>(); TestNode3 temp = reservedList.head.nextNode; while (temp != null ){ TestNode3 curNode = reservedList.getNode(temp.num); stack.push(curNode); temp = temp.nextNode; } while (stack.size() > 0 ){ System.out.println(stack.pop()); } } public static TestNode3 reverseLinkedList2 (TestNode3 headNode) { TestNode3 newHead = new TestNode3 (0 ,null ,null ); if (headNode == null || headNode.nextNode == null ){ return headNode; } TestNode3 pre = null ; TestNode3 next = null ; TestNode3 temp = headNode.nextNode; while (temp != null ){ next = temp.nextNode; pre = newHead.nextNode; newHead.nextNode = temp; temp.nextNode = pre; temp = next; } return headNode.nextNode = newHead.nextNode; } public static SingleLinkedList3 reverseLinkedList (SingleLinkedList3 linkedList) { SingleLinkedList3 singleLinkedList3 = new SingleLinkedList3 (); TestNode3 newHead = singleLinkedList3.head; TestNode3 temp = linkedList.head.nextNode; TestNode3 curNext = null ; if (temp == null || temp.nextNode == null ){ return linkedList; } while (temp != null ){ curNext = temp.nextNode; temp.nextNode = newHead.nextNode; newHead.nextNode = temp; temp = curNext; } return singleLinkedList3; } } class SingleLinkedList3 { public TestNode3 head = new TestNode3 (0 ,null ,null ); public TestNode3 getAssignNode (int index) { TestNode3 temp = head; if (temp.nextNode == null ){ return null ; } int nodes = countList(); int num = nodes - index + 1 ; if (num > 0 && num <= nodes){ return getNode(num); }else { return null ; } } public int countList () { TestNode3 temp = head; int count = 0 ; while (true ){ if (temp.nextNode == null ){ return count; }else { count += 1 ; temp = temp.nextNode; } } }
双向链表 特点:可以实现自我删除;双向寻找
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 class DoubleSidedLinkedList { public Node head = new Node (0 ,null ,null ); public void showLinkedList () { if (head.next == null ){ System.out.println("当前链表为空" ); return ; } Node temp = head.next; while (temp != null ){ System.out.println(temp); temp = temp.next; } } public void add (Node node) { if (head.next == null ){ head.next = node; node.pre = head; return ; } Node temp = head.next; while (true ){ if (temp.num == node.num){ System.out.println("当前添加的节点" + node + "在链表中已存在,添加失败" ); break ; } int curNum = temp.num; int preNum = temp.pre.num; int nodeNum = node.num; if (preNum < nodeNum && nodeNum < curNum){ temp.pre.next = node; node.next = temp; node.pre = temp.pre; temp.pre = node; break ; } if (temp.next == null ){ temp.next = node; node.pre = temp; break ; }else { temp = temp.next; } } } public void update (Node node) { if (head.next == null ){ System.out.println("链表为空" ); return ; } Node temp = head.next; while (temp != null ){ if (temp.num == node.num){ temp.name = node.name; temp.nickName = node.nickName; break ; }else { temp = temp.next; } } } public void delete (int nodeNum) { if (head.next == null ){ System.out.println("链表为空" ); return ; } Node temp = head.next; while (true ){ if (temp.num == nodeNum){ temp.pre.next = temp.next; if (temp.next != null ){ temp.next.pre = temp.pre; } break ; }else { temp = temp.next; if (temp == null ){ System.out.println("链表中不存在该节点,无法删除" ); break ; } } } } } class Node { public int num; public String name; public String nickName; public Node pre; public Node next; public Node () { } public Node (int num, String name, String nickName) { this .num = num; this .name = name; this .nickName = nickName; } }
环形链表
单向环形链表应用场景:约瑟夫问题
约瑟夫问题:设编号为1,2,… n的n个人围坐一圈,约定编号为k(1<=k<=n)的人从1开始报数,数
到m 的那个人出列,它的下一位又从1开始报数,数到m的那个人又出列,依次类推,
直到所有人出列为止,由此产生一个出队编号的序列。
解决思路:用一个不带头结点的循环链表来处理,先构成一个有n个结点的单循环链表(单向环形链表),
然后由k结点起从1开始计数,计到m时,对应结点从链表中删除,然后再从被删除结点的下一个结点
又从1开始计数,直到最后一个结点从链表中删除算法结束。
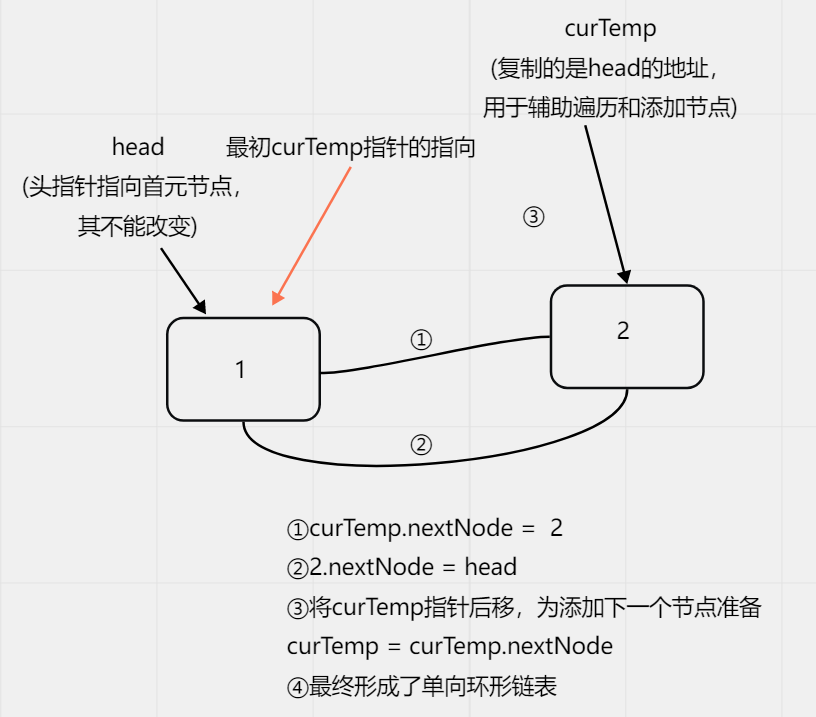
具体做法:①创建一个单向环形链表,并添加数据
②将head的地址复制给一个临时指针curTemp
③在进行报数时,将head和curTemp指针移动到指定位置
④head指针所在位置即为需要出圈的节点,将curTemp指针的下一个节点指向head指针的下一个
⑤将head指针指向其下一个节点,即为下次要开始报数的节点。
⑥等head指针和curTemp指针位于同一个位置时,代表链表中只剩下一个节点,将其最终出圈
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 class SingleRingLinkedList { public RingNode head = new RingNode (1 ); public RingNode curTemp = head; public void add (int num) { if (num < 1 ){ System.out.println("输入的节点不正确" ); return ; } for (int i = 2 ; i <= num; i++) { RingNode node = new RingNode (i); if (head.nextNode == null ){ head.nextNode = node; node.nextNode = head; curTemp = curTemp.nextNode; }else { curTemp.nextNode = node; node.nextNode = head; curTemp = curTemp.nextNode; } } } public void JosephuQuestionResolve (int startNum,int countNum,int LinkedListNum) { if (head == null || startNum < 1 || startNum > LinkedListNum){ System.out.println("链表中没有任何节点" ); return ; } for (int i = 1 ; i <= startNum - 1 ; i++) { head = head.nextNode; curTemp = curTemp.nextNode; } while (true ) { for (int i = 1 ; i <= countNum - 1 ; i++) { head = head.nextNode; curTemp = curTemp.nextNode; } System.out.println("编号:" + head.num + "的节点出圈," + head); curTemp.nextNode = head.nextNode; head = head.nextNode; if (head == curTemp) { System.out.println("链表中最后一个节点出圈,编号:" + head.num + "的节点出圈," + head); break ; } } } public void showRingLinkedList () { if (head.nextNode == null ){ System.out.println("链表为空" ); return ; } RingNode temp = head; while (true ){ System.out.println(temp); temp = temp.nextNode; if (temp == head){ break ; } } } } class RingNode { public int num; public RingNode nextNode; public RingNode () { } public RingNode (int num) { this .num = num; } @Override public String toString () { return "RingNode{" + "num=" + num + '}' ; } }
栈 概念:元素的拆入和删除只能在线性表的同一端进行操作,允许插入和删除的一端称为栈顶,另一个固定的一端称为栈底
特点:一个先进后出
e.g:栈的应用案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 public class CalculatorStack { public static void main (String[] args) { CustomizedStack numStack = new CustomizedStack (10 ); CustomizedStack charStack = new CustomizedStack (10 ); String string = "30*2-6*9+1" ; String tooMany = "" ; char [] chars = string.toCharArray(); for (int i = 0 ; i < chars.length; i++) { if (!numStack.isCh(chars[i])){ tooMany += chars[i]; if (i == chars.length -1 ){ numStack.addData(chars[i] - 48 ); }else if (charStack.isCh(chars[i+1 ])){ numStack.addData(Integer.parseInt(tooMany)); }else { continue ; } tooMany = "" ; }else if (charStack.isCh(chars[i])){ if (charStack.isEmpty()){ charStack.addData(chars[i]); }else { int curPriority = charStack.charPriority(chars[i]); int ch = charStack.stackTopValue(); int stackPriority = charStack.charPriority(ch); if (curPriority <= stackPriority){ int num1 = numStack.popData(); int num2 = numStack.popData(); int c = charStack.popData(); int result = numStack.count(num1, num2,c); numStack.addData(result); charStack.addData(chars[i]); }else { charStack.addData(chars[i]); } } } } while (true ){ if (charStack.isEmpty()){ break ; } int num1 = numStack.popData(); int num2 = numStack.popData(); int ch = charStack.popData(); int result = numStack.count(num1,num2,ch); numStack.addData(result); if (charStack.getTop() == -1 ){ break ; } } } } class CustomizedStack { private int arraySize; private int top = -1 ; private int bottom = -1 ; private int [] array; public CustomizedStack () { } public CustomizedStack (int arraySize) { this .arraySize = arraySize; this .array = new int [this .arraySize]; } @Override public String toString () { return "CustomizedStack{" + "top=" + top + ", bottom=" + bottom + '}' ; } public int getTop () { return top; } public void showStack () { if (isEmpty()){ System.out.println("栈中没有任何数据" ); return ; } for (int i = top; i > bottom; i--){ System.out.println(array[i]); } } public boolean isFull () { return top >= arraySize - 1 ; } public boolean isEmpty () { return top = = -1 ; } public void addData (int num) { if (isFull()){ System.out.println("栈已满,添加失败" ); return ; } top++; array[top] = num; } public int popData () { if (isEmpty()){ System.out.println("栈中没有任何数据" ); return -2 ; } return array[top--]; } public int charPriority (int ch) { if (ch == '*' || ch == '/' ){ return 1 ; }else if (ch == '+' || ch == '-' ){ return 0 ; }else { return -1 ; } } public boolean isCh (char ch) { return ch = = '*' || ch == '/' || ch == '-' || ch == '+' ; } public int count (int num1,int num2,int ch) { int result = 0 ; switch (ch){ case '+' : result = num1 + num2; break ; case '-' : result = num2 - num1; break ; case '*' : result = num2 * num1; break ; case '/' : result = num2 / num1; break ; } return result; } public int stackTopValue () { return array[top]; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public class InversePolandNotation { public static void main (String[] args) { String suffixExpression = "4 5 * 8 - 60 + 8 2 / +" ; String[] array = suffixExpression.split(" " ); int result = InversePolandNotation.ReversePolishNotationCount(array); System.out.println("后缀表达式的结果是:" + result); public static int ReversePolishNotationCount (String[] array) { if (array.length == 0 ){ throw new RuntimeException ("传入的数组为空" ); } int result = 0 ; Stack<String> stack = new Stack <>(); for (int i = 0 ; i < array.length; i++) { if (array[i].matches("\\d+" )){ stack.push(array[i]); }else { int num1 = Integer.parseInt(stack.pop()); int num2 = Integer.parseInt(stack.pop()); if ("+" .equals(array[i])){ result = num2 + num1; }else if ("-" .equals(array[i])){ result = num2 - num1; }else if ("*" .equals(array[i])){ result = num2 * num1; }else if ("/" .equals(array[i])){ result = num2 / num1; }else { throw new RuntimeException ("当前字符不合法" ); } stack.push(String.valueOf(result)); } } return result; } }
三种不同的表达式 —> 表达式互转的理解
前缀表达式又称波兰表达式
特点:前缀表达式 都以运算符开头,以操作数结尾 从右至左
e.g:中缀表达式的(3+4)*5-6 对应的前缀表达式是 - * + 3 4 5 6
中缀表达式是最熟悉和常见的计算表达式,中缀表达式通常有小括号
后缀表达式又称逆波兰表达式
特点:后缀表达式 都以操作数开头,以运算符结尾 从左至右
e.g:中缀表达式的(3+4)*5-6 对应的后缀表达式是 3 4 + 5 * 6 -
中缀表达式转后缀表达式思路及代码示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 public static int ReversePolishNotationCount (String[] array) { if (array.length == 0 ){ throw new RuntimeException ("传入的数组为空" ); } int result = 0 ; Stack<String> stack = new Stack <>(); for (int i = 0 ; i < array.length; i++) { if (array[i].matches("\\d+" )){ stack.push(array[i]); }else { int num1 = Integer.parseInt(stack.pop()); int num2 = Integer.parseInt(stack.pop()); if ("+" .equals(array[i])){ result = num2 + num1; }else if ("-" .equals(array[i])){ result = num2 - num1; }else if ("*" .equals(array[i])){ result = num2 * num1; }else if ("/" .equals(array[i])){ result = num2 / num1; }else { throw new RuntimeException ("当前字符不合法" ); } stack.push(String.valueOf(result)); } } return result; } public static List inFixExpression (String expression) { if ("" .equals(expression)){ throw new RuntimeException ("表达式为空" ); } List<String> list = new ArrayList <>(); String string = "" ; char [] array = expression.toCharArray(); for (int i = 0 ; i < array.length; i++) { if (i == array.length - 1 ){ list.add(String.valueOf(array[i])); break ; } if (InversePolandNotation2.isCh(array[i])){ list.add(String.valueOf(array[i])); }else { string += String.valueOf(array[i]); if (!InversePolandNotation2.isCh(array[i+1 ])){ continue ; }else { list.add(string); } } string = "" ; } return list; } public static List<String> inFixToSuffixExpression (List<String> list) { String[] inFix = list.toArray(new String [0 ]); List<String> suffixList = new ArrayList <>(); Stack<String> charStack = new Stack <>(); for (int i = 0 ; i < inFix.length; i++) { if (!inFix[i].matches("\\d+" )){ while (true ){ if (charStack.empty() || array[i] == charStack.peek() && charStack.peek() == '(' ){ charStack.push(array[i]); break ; } else if (array[i] == '(' ){ charStack.push(array[i]); break ; } else if (array[i] == ')' ){ while (charStack.peek() != '(' ){ Character first = charStack.pop(); numStack.push(first); } charStack.pop(); break ; } else { Character top = charStack.peek(); int topLevel = InversePolandNotation.charPriority(top); int curLevel = InversePolandNotation.charPriority(array[i]); if (curLevel > topLevel){ charStack.push(array[i]); break ; }else { Character c1 = charStack.pop(); numStack.push(c1); charStack.push(array[i]); break ; } } } }else { suffixList.add(inFix[i]); } } while (!charStack.empty()){ String theEnd = charStack.pop(); suffixList.add(theEnd); } return suffixList; } public static boolean isCh (char ch) { return ch = = '*' || ch == '/' || ch == '-' || ch == '+' || ch == '(' ||ch == ')' ; } public static int charPriority (String ch) { if ("*" .equals(ch) ||"/" .equals(ch)){ return 1 ; }else if ("+" .equals(ch) ||"-" .equals(ch)){ return 0 ; }else if ("(" .equals(ch) ||")" .equals(ch)){ return -1 ; }else { return -2 ; } }
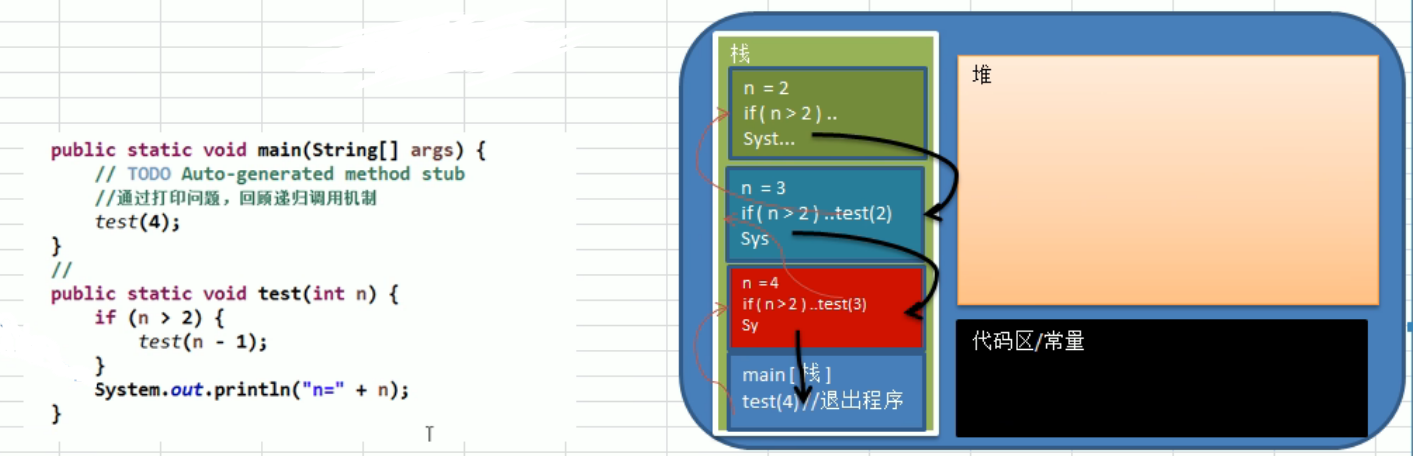
递归 递归调用规则:
①当程序执行到一个方法时,就会开辟一个独立的空间(栈)
②每个空间的数据(局部变量),都是独立的
但是如果方法中的形参使用的引用数据类型,则所有方法使用的都是该引用数据类型的变量
③递归必须是有方向的,也就是必须向退出递归的方向进行
④当方法执行完毕,或者遇到return就会返回,遵循谁调用返回给谁的原则。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 public class MiGongTest { public static void main (String[] args) { int [][] map = new int [8 ][7 ]; for (int i = 0 ; i < map.length; i++) { for (int j = 0 ; j < map[i].length; j++) { if (i == 0 || j == 0 || i == map.length-1 || j == 6 ){ map[i][j] = 1 ; }else if (i == 3 && j == 1 || i == 3 && j == 2 ){ map[i][j] = 1 ; } else { map[i][j] = 0 ; } } } } public static boolean isFindWay (int [][] map,int i,int j) { if (map[6 ][5 ] == 2 ){ return true ; }else { if (map[i][j] == 0 ){ map[i][j] = 2 ; if (isFindWay(map,i+1 ,j)){ return true ; }else if (isFindWay(map,i,j+1 )){ return true ; }else if (isFindWay(map,i-1 ,j)){ return true ; }else if (isFindWay(map,i,j-1 )){ return true ; }else { map[i][j] = 3 ; return false ; } }else { return false ; } } } }
八皇后问题
使用一个一维数组记录所有皇后成功放置的位置
例如 array[8] = {0,4,7,5,2,6,1,3} 数组下标表示皇后在第几行,数组下标对应的值表示皇后在第几列
for是水平移动皇后,递归是继续摆下一个皇后,回溯是回到上一行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 public class QueenRecursion { int max = 8 ; int [] queenArray = new int [max]; static int count = 0 ; public static void main (String[] args) { QueenRecursion queenRecursion = new QueenRecursion (); queenRecursion.check(0 ); System.out.println("result:" + count); } private void check (int n) { if (n == max){ showQueenArray(); return ; } for (int i = 0 ; i < max; i++) { queenArray[n] = i; if (judge(n)){ check(n+1 ); } } } private boolean judge (int n) { for (int i = 0 ; i < n; i++) { if (queenArray[i] == queenArray[n] || Math.abs(n-i) == Math.abs(queenArray[n] - queenArray[i])){ return false ; } } return true ; } private void showQueenArray () { for (int i = 0 ; i < queenArray.length; i++) { System.out.print(queenArray[i] + "\t" ); } count += 1 ; System.out.println(); } }
①递归是一种算法结构,回溯是一种算法思想,回溯法是用递归实现
②递归的定义:通常来说,为了描述问题的某一状态,必须用到该状态的上一个状态;而如果要
描述上一个状态,又必须用到上一个状态的上一个状态…… 这样用自己来定义自己的方法 就是递归。
回溯的定义:回溯法是一种选优搜索法,按选优条件向前搜索,以达到目标。但当探索到某一步时,
发现原先选择并不优或达不到目标,就退回一步重新选择 ,这种走不通就退回再走的技术为回溯法。
③回溯算法其实是一种试探 ,该方法放弃关于问题规模大小的限制,并将问题的方案按某种顺序逐一
枚举和试验。发现当前方案不可能有解时,就选择下一个方案,倘若当前方案不满足问题的要求时,
继续扩大当前方案的规模,并继续试探。如果当前方案满足所有要求时,该方案就是问题的一个解。
放弃当前方案,寻找下一介方案的过程称为回溯。 而递归算法依赖与前一步的结果,它的结果来源于
一条主线,是确定的,而不是试探的结果, 这就是其与回溯的区别,而在很多情况下,回溯与递归算法
是在一起使用的。
举个其他博主的提供例子:我们在路上走着,前面是一个多岔路口,因为我们并不知道应该走哪条路,
所以我们需要尝试。尝试的过程就是一个函数。我们选择了一个方向,后来发现又有一个多岔路口,
这时候又需要进行一次选择。所以我们需要在上一次尝试结果的基础上,再做一次尝试,即在函数内部
再调用一次函数,这就是递归的过程。这样重复了若干次之后,发现这次选择的这条路走不通,这时候
我们知道我们上一个路口选错了,所以我们要回到上一个路口重新选择其他路,这就是回溯的思想。
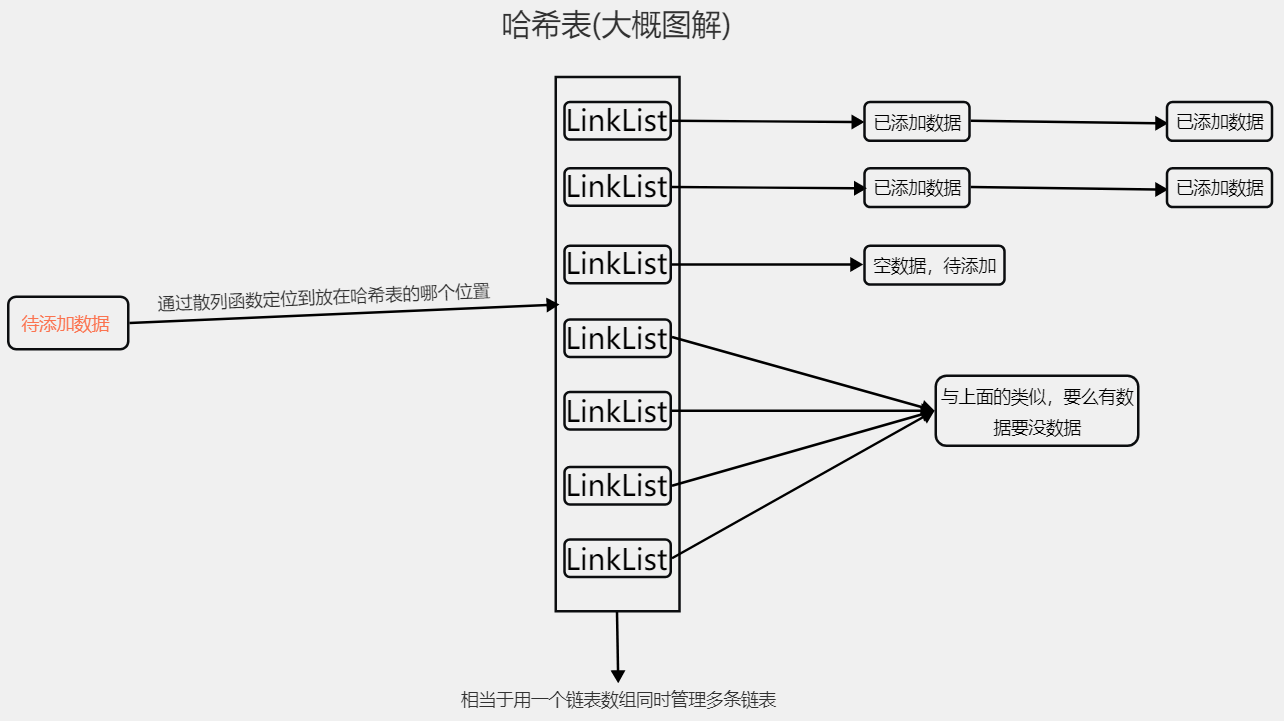
哈希表 散列表(Hash table,也叫哈希表):根据关键码值(Key value)而直接进行访问的数据结构。
它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
这个映射函数叫做散列函数,存放记录的数组叫做散列表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class EmpLinkList { private Employee headEmp; } public class MyHashTable { private static EmpLinkList[] empLinkListArray; private static int arrSize; public MyHashTable (int size) { arrSize = size; empLinkListArray = new EmpLinkList [size]; for (int i = 0 ; i < empLinkListArray.length; i++) { empLinkListArray[i] = new EmpLinkList (); } } public int hashMethod (int id) { return id % arrSize; } }
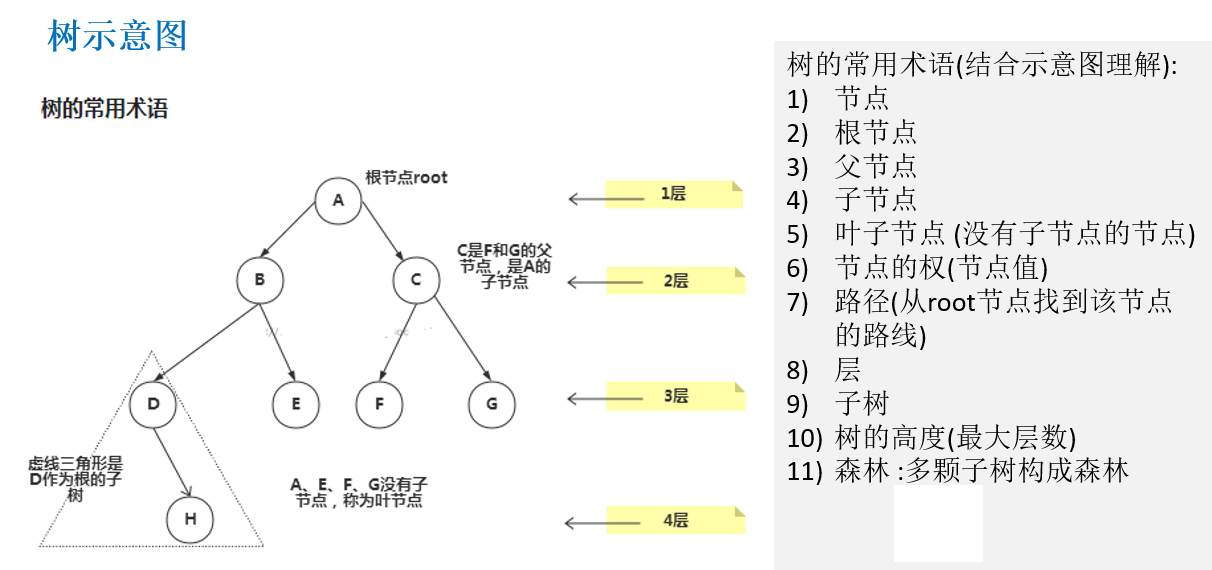
树结构 概念
数组在对于查找的效率很快,对于频繁的插入和删除效率较低
链表对频繁的插入和删除效率较高,但对于查找的效率较低
树既能提高数据的查找读取的效率,同时也能保证数据的插入、删除、修改的速度。
无序二叉树 二叉树:每个节点最多只能有两个子节点。二叉树的子节点分为左节点和右节点。
满二叉树:所有叶子节点都在最后一层,并且结点总数= 2^n -1 , n 为层数
完全二叉树:所有叶子节点都在最后一层或者倒数第二层,而且最后一层的叶子节点在左边连续,
倒数第二层的叶子节点在右边连续。若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的
结点数都达到最大个数(即1~h-1层为一个满二叉树),第 h 层所有的结点都连续集中在最左边。
遍历
前序遍历:先遍历根结点,再遍历左子树,最后遍历右子树
中序遍历:先遍历左子树,再遍历根结点,最后遍历右子树
后序遍历:先遍历左子树,再遍历右子树,最后遍历根结点
所谓前序、中序、后序遍历就是就是针对根节点所在的位置而言的。
代码过长,具体到DataStucture目录下的tree包下查看
查找 基本就是在遍历的基础上进行的,只需要将打印语句换成判断条件并返回查找到的节点即可
删除 具体思路:1.先判断当前删除的是不是root根节点,是的话直接置空root整个树
2.不是根节点的话,先判断删除的是否为根节点的左子节点或根节点的右子节点
3.如果都不是,就先开始向左递归查找对应节点
4.如果左边递归找不到,再开始向右递归查找对应节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public void deleteNode (int id) { HeroNode leftNode = this .getLeft(); HeroNode rightNode = this .getRight(); if (leftNode != null && rightNode != null ) { if (leftNode.getId() == id){ this .setLeft(null ); return ; } if (rightNode.getId() == id){ this .setRight(null ); return ; } } if (this .getLeft() != null ){ this .getLeft().deleteNode(id); } if (this .getRight() != null ){ this .getRight().deleteNode(id); } }
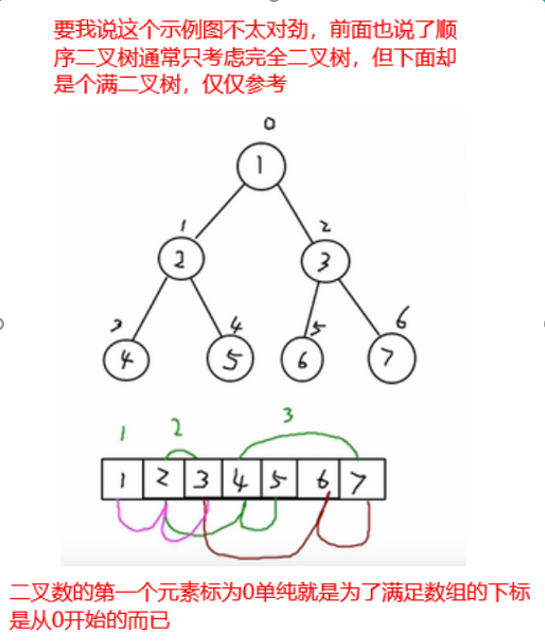
顺序存储二叉树
顺序存储,指的是连续的空间如数组方式存储树的节点
数组存储方式和树的存储方式可以相互转换,数组可以转换成树,树也可以转换成数组
①顺序二叉树通常只考虑完全二叉树
②第n个元素的左子节点为 2 * n + 1
③第n个元素的右子节点为 2 * n + 2
④第n个元素的父节点为 (n-1) / 2
n : 表示二叉树中的第几个元素(按0开始编号�如图所示);实际上n也对应这元素在数组中的下标
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public void preOrder (int index) { if (array == null || array.length == 0 ){ System.out.println("数组为空不能执行前序遍历" ); return ; } System.out.println(array[index]); int left = 2 *index+1 ; if (left < array.length){ preOrder(left); } int right = 2 *index+2 ; if (right < array.length){ preOrder(right); } }
线索二叉树
公式n+1的推导:当有n个节点时,每个节点有两个指针,即总共可用指针为2n
但是除了根节点以外,其他节点头上都有一条指针指向它,因此需要n-1个指针
例如6个节点,你会发现总共有5个节点头上有指针连接
所以剩余可用指针(即为空指针)为 2n-(n-1) ==> n+1
线索二叉树(Threaded BinaryTree):n个结点的二叉链表中含有n+1个空指针域。
存放指向该结点在某种遍历次序下的前驱和后继结点的指针(这种附加的指针称为”线索”)。而加上了线索的
二叉链表称为线索链表,相应的二叉树称为线索二叉树。
前驱结点:一个结点的前一个结点 后继结点:一个结点的后一个结点
根据线索性质的不同,可分为前序线索二叉树、中序线索二叉树和后序线索二叉树三种
在完全二叉树的情况下,叶子节点和某些子树节点的左右指针没有完全利用上,
通过线索二叉树能够充分利用各个节点的左右指针
实际就是先通过左边中序遍历查找到最左边的叶子节点,再判断一下此叶子节点左右指针是否需要线索化,
如何左右都需要线索化,则先只线索化左边指针,让其指向前驱节点(没有前驱节点则为null),因为此叶子节点
是第一个被遍历的,它前面没有其他节点了。至于右边的指针,则留到下一个节点判断左右指针线索化的时候
完成(但前提是需要使用一个外界公共属性保存各个节点的上一个节点,便于后继节点的指向,这个属性的值
不能随着压栈操作的结束而消失,否则线索化会失败)。并将这个公共属性的值修改为当前节点值。最后才进行
线索化右边指针,当这个公共属性不为空且它的右指针为空时代表就是上个未进行右指针线索化的节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public void midThreadedBinaryTreeTest (HeroNode node) { if (node == null ){ return ; } midThreadedBinaryTreeTest(node.getLeft()); if (node.getLeft() == null ){ node.setLeft(ThreadedBinaryTree.pre); node.setLeftType(true ); } if (ThreadedBinaryTree.pre != null && ThreadedBinaryTree.pre.getRight() == null ){ ThreadedBinaryTree.pre.setRight(node); ThreadedBinaryTree.pre.setRightType(true ); } ThreadedBinaryTree.pre = node; midThreadedBinaryTreeTest(node.getRight()); }
因为线索化的二叉树不能再使用之前的遍历方式,因此在节点中添加了leftType和rightType属性
表示是指向前驱、后继节点还是左、右子树,中序是先从左子树开始的,而线索二叉树的第一个
元素有一个最明显的特征,即其的leftType属性必然是true,从而找到左子树最底层的叶子节点,
由于后继节点表示一个节点的下一个节点,因此可以通过循环比较节点的rightType属性,如果
是true代表指向其后继节点,可以直接输出该节点,如果false,表示其指向其子树,则跳出循环,
用当前不是指向后继节点的节点替代原来的node,继续重复上面的步骤,直至找到一个为null的
节点,最终结束遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public static void showThreadedBinaryTree (HeroNode node) { while (node != null ){ while (!node.leftType){ node = node.getLeft(); } System.out.println(node); while (node.rightType){ node = node.getRight(); System.out.println(node); } node = node.getRight(); } }
赫夫曼树 赫夫曼树(哈夫曼树):即给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度(wpl)
最小,称这样的二叉树为最优二叉树,赫夫曼树是带权路径长度最短的树,权值越大的结点离根越近
路径:在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。
路径长度:通路中分支的数目称为路径长度,若根结点的层数为1,则从根结点到第L层结点的路径长度为L-1
结点的权:若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。
结点的带权路径长度:从根结点到该结点之间的路径长度与该结点的权的乘积
树的带权路径长度:树的带权路径长度规定为所有叶子结点的带权路径长度之和,记为WPL(weighted path length) 。
1.将无序序列从小到大进行排序, 将每一个数据看成一个节点 , 而每个节点又看成是一颗最简单的二叉树(左右节点为空)
2.取出当前前两个根节点权值较小的二叉树
3.组成一颗新的二叉树, 该新的二叉树的根节点的权值是前面两颗根节点权值较小的二叉树之和
再设置此二叉树的左右节点,最后将这颗新的二叉树加入序列,以根节点的权值大小再次进行排序
4.不断重复 1-2-3 的步骤,直到数列中,所有的数据都被处理,此时就得到一颗赫夫曼树
(此处案例以集合来表示各个二叉树,当所有数据被处理后,集合中仅剩一个元素,此元素就是赫夫曼数的根节点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public static Node createHuffManTree (int [] array) { List<Node> nodes = new ArrayList <>(); for (int i: array){ nodes.add(new Node (i)); } Collections.sort(nodes); while (nodes.size() > 1 ){ Node leftNode = nodes.get(0 ); Node rightNode = nodes.get(1 ); Node parent = new Node (leftNode.value + rightNode.value); parent.left = leftNode; parent.right = rightNode; nodes.remove(leftNode); nodes.remove(rightNode); nodes.add(parent); Collections.sort(nodes); } return nodes.get(0 ); }
二叉排序树
二叉排序树Binary Sort(Search) Tree)
任何一个非叶子节点,要求左子节点的值比当前节点的值小,右子节点的值比当前节点的值大。
如果有相同的值,可以将该节点放在左子节点或右子节点
得先判断当前待删除的节点是否存在,再得考虑这三种情况:
1.当前待删除的节点为叶子节点
叶子节点为父节点的左子节点 或 叶子节点为父节点的右子节点
2.当前待删除的节点只有一个子树(只有左子树或右子树)
待删除节点是父节点的左节点,待删除节点有个左节点
待删除节点是父节点的左节点,待删除节点有个右节点
待删除节点是父节点的右节点,待删除节点有个左节点
待删除节点是父节点的右节点,待删除节点有个右节点
3.当前待删除的节点有两个子树
两种方法:①则需要找到父节点的右子树的最小值,因为右子树的最小值比左子树的所有值都要大)
②需要找到待删除节点的左子树的最大值,因为左子树的最大值比右子树的所有值都要小)
具体代码到tree.binarysorttree包下查看
平衡二叉树
平衡二叉树是基于二叉排序树的基础上出现的,
又被称为AVL树, 可以保证查询效率较高。
它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
平衡二叉树的常用实现方法有红黑树、AVL、替罪羊树、Treap、伸展树等。
在通过一个有序的数组[1,2,3,4,5,6,7,8]创建一个二叉树会出现此树左子树都为空,整个二叉树表现得像个
单向链表,虽然插入速度不受影响,但查询效率大大减低,因为每次都需要比较左子树。
当前二叉树的左子树与右子树高度差大于1,需要向右旋转,降低左子树高度
当前二叉树的右子树与左子树高度差大于1,需要向左旋转,降低右子树高度
具体代码到tree.avl包下查看
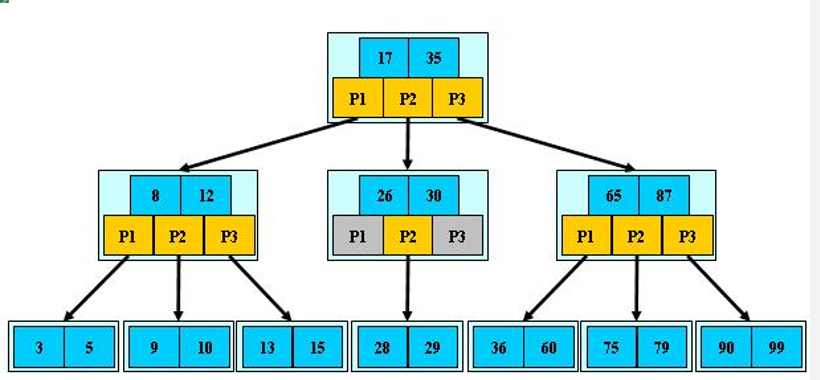
多路查找树
多路查找树也称为多叉树,它允许每个节点可以有更多的数据项和更多的子节点
二叉树需要从数据库或者磁盘中加载到内存,如果二叉树的节点过多就会导致I/O操作频繁,且普通二叉树的节点
过多会极大降低操作效率。
节点度:当前节点下的所有子节点的个数
树的度:所有节点度的最大值
2-3树
2-3树是由二节点和三节点构成的树。2-3树是最简单的B树,且2-3树依旧具有二叉排序树的要求
2-3树的特点
2-3树的所有叶子节点都在同一层.(只要是B树都满足这个条件)
有两个子节点的节点叫二节点,二节点要么没有子节点,要么有两个子节点.
有三个子节点的节点叫三节点,三节点要么没有子节点,要么有三个子节点.
插入规则
当按照2-3树的特点插入一个数到某个节点时,不能满足上面三个要求,就需要拆,先向上拆,
如果上层满,则拆本层,拆后仍然需要满足上面3个条件。对于三节点的子树的值大小仍然遵守
(BST 二叉排序树)的规则
B树 B-tree树即B树,B即Balanced,平衡的意思。
B树的特点(其搜索性能等价于在关键字全集内做一次二分查找)
①B树的阶:节点的最多子节点个数。比如2-3树的阶是3,2-3-4树的阶是4
②B-树的搜索:从根结点开始,对结点内的关键字(有序)序列进行二分查找,
③如果命中则结束,否则进入查询关键字所属范围的儿子结点;不断重复,直到所对应的节点指针为空
④关键字(查找的目标值)集合分布在整颗树中, 即目标值有可能是叶子节点或是非叶子节点
⑤关键字(查找的目标值)搜索有可能在非叶子结点结束。
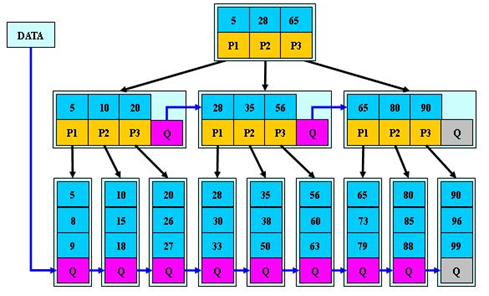
B+树
B+树是B树的变体,也是一种多路搜索树。
B+树的特点(其性能也等价于在关键字全集做一次二分查找)
①B+树的搜索与B树也基本相同,区别是B+树只有达到叶子结点才命中(B树可以在非叶子结点命中),
②所有关键字都出现在叶子结点的链表中(即数据只能在叶子节点【也叫稠密索引】),且链表中的
关键字(数据)恰好是有序的。
③不可能在非叶子结点命中
④非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层,
更适合文件索引系统
B*树
B*树是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针
①B* 树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3,而B+树的块的最低使用率为1/2。
②B*树分配新结点的概率比B+树要低,空间使用率更高
Q代表指向下一个节点
红黑树 实现红黑树的关键:变色和旋转(左旋或右旋)
①每个节点不是黑色就是红色(默认根节点为黑色,每一个插入的节点开始默认为红色)
②根节点为黑色
③红色节点的父节点和子节点不能为红色(或者说每个红色节点必须有两个黑色子节点)
④每个叶子节点是黑色。 [注意:这里叶子节点,是指为空的叶子节点!]
⑤从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点
①平衡二叉树的左右子树的高度差绝对值不超过1,但是红黑树在某些时刻可能会超过1,但还符合红黑树的五个条件
②二叉树只要不平衡就会进行旋转,而红黑树不符合规则时,有些情况只用改变颜色不用旋转,就能达到平衡。
图结构
因为在某种情况下需要表示多对多的关系,而线性表和树不能满足这个要求
图是一种数据结构,其中结点可以具有零个或多个相邻元素。
两个结点之间的连接称为边。 结点也可以称为顶点。
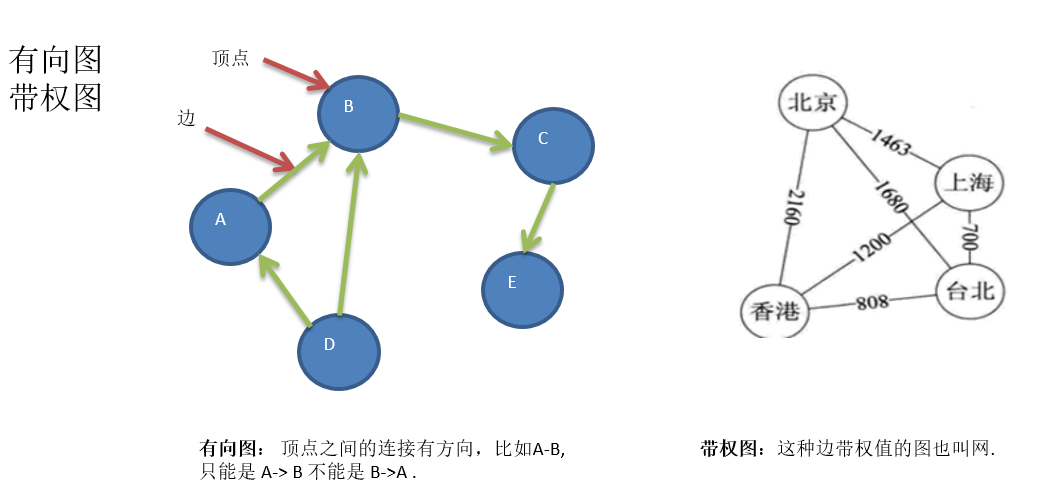
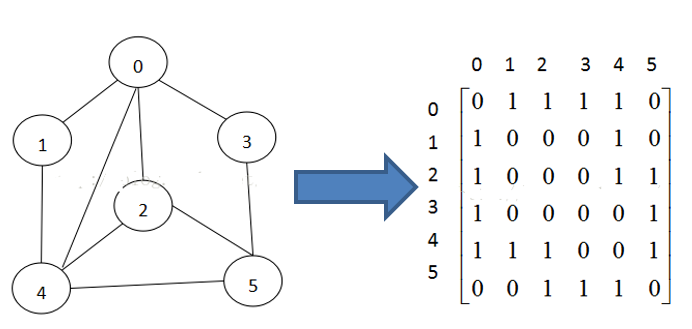
两种方式:二维数组表示(邻接矩阵)和 链表表示(邻接表)。
邻接矩阵:表示图形中顶点之间相邻关系的矩阵,对于n个顶点的图而言,矩阵是的row和col表示的是1….n个点。
邻接矩阵需要为每个顶点都分配n个边的空间,其实有很多边都是不存在,会造成空间的一定损失.
如何理解无向图的邻接矩阵是对称的?
如果记邻接矩阵为A,如果顶点i和顶点j,有一条边,那么矩阵元素值A(i,j)和A(j,i)是一样的,所以A是对称的。
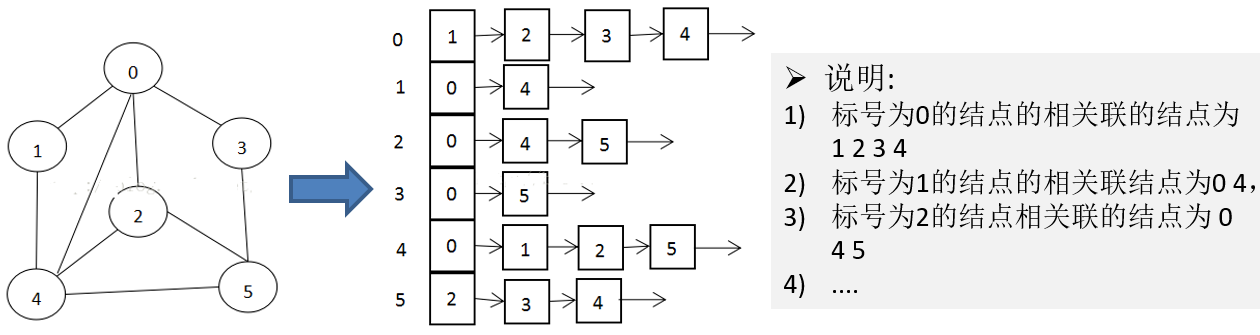
邻接表:由数组+链表组成邻接表的实现,它只关心存在的边,不关心不存在的边,因此没有空间浪费
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 public class GraphDemo { private static ArrayList<String> vertexList; private static int [][] edges; private static int numOfEdge; public static void main (String[] args) { GraphDemo graph = new GraphDemo (5 ); String[] val = {"A" ,"B" ,"C" ,"D" ,"E" }; for (String s : val) { graph.insertVertex(s); } graph.insertEdge(0 ,1 ,1 ); graph.insertEdge(0 ,2 ,1 ); graph.insertEdge(1 ,2 ,1 ); graph.insertEdge(1 ,3 ,1 ); graph.insertEdge(1 ,4 ,1 ); graph.showGraphMatrix(); } public GraphDemo (int num) { edges = new int [num][num]; vertexList = new ArrayList <>(num); } public void insertVertex (String vertex) { vertexList.add(vertex); } public void insertEdge (int v1,int v2,int value) { edges[v1][v2] = value; edges[v2][v1] = value; numOfEdge++; }
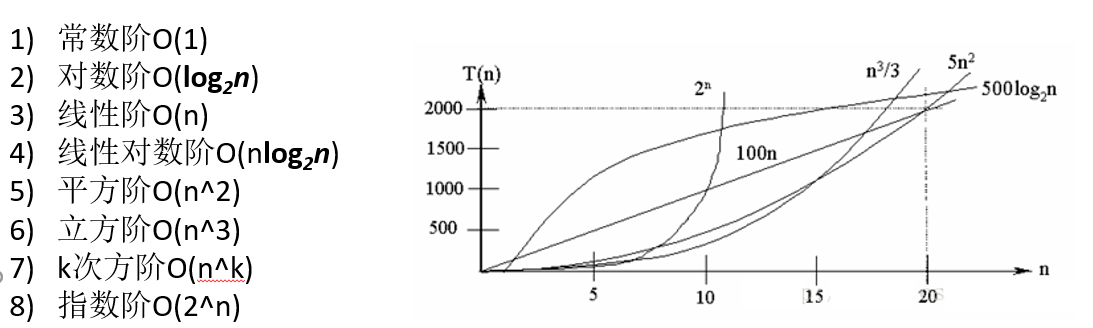
算法 前置知识 时间频度 语句执行次数 被称为语句频度或时间频度,记为**T(n)**。
一个算法所花的时间与算法中语句的执行次数成正比例关系
随着程序规模的增大时间频度通常可以忽略常数项、低次项、系数,进而影响算法的时间复杂度。
时间复杂度
若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n) / f(n) 的极限值为不等于零的常数,
则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
计算时间复杂度的方法:
①当时间频度为常数时,则时间复杂度为T(n)= O(1)
②当时间频度为多项式时,去除低阶项和高阶项的系数,但必须保留高阶项的次项
常见的时间复杂度
参考上面的O(n²) 去理解,O(n³)相当于三层n循环
参考上面的O(n²) 去理解,O(n*k)相当于k层n循环
①平均时间复杂度是指所有可能的输入实例均以等概率出现的情况下,该算法的运行时间。
②最坏情况下的时间复杂度称最坏时间复杂度。一般讨论的时间复杂度均是最坏情况下的时间复杂度。
因为这保证了算法的运行时间不会比最坏情况更长。
③平均时间复杂度和最坏时间复杂度是否一致,和算法有关
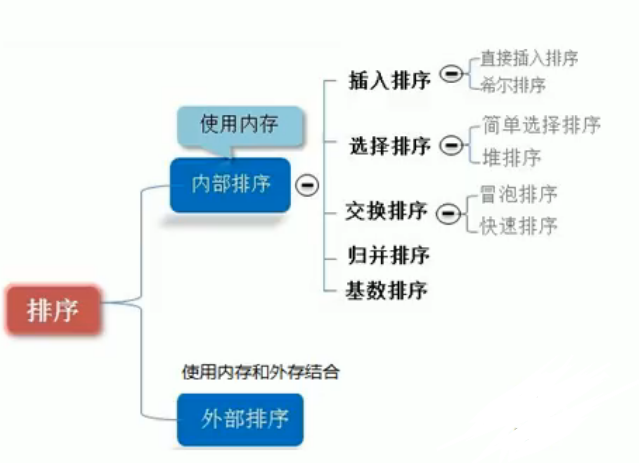
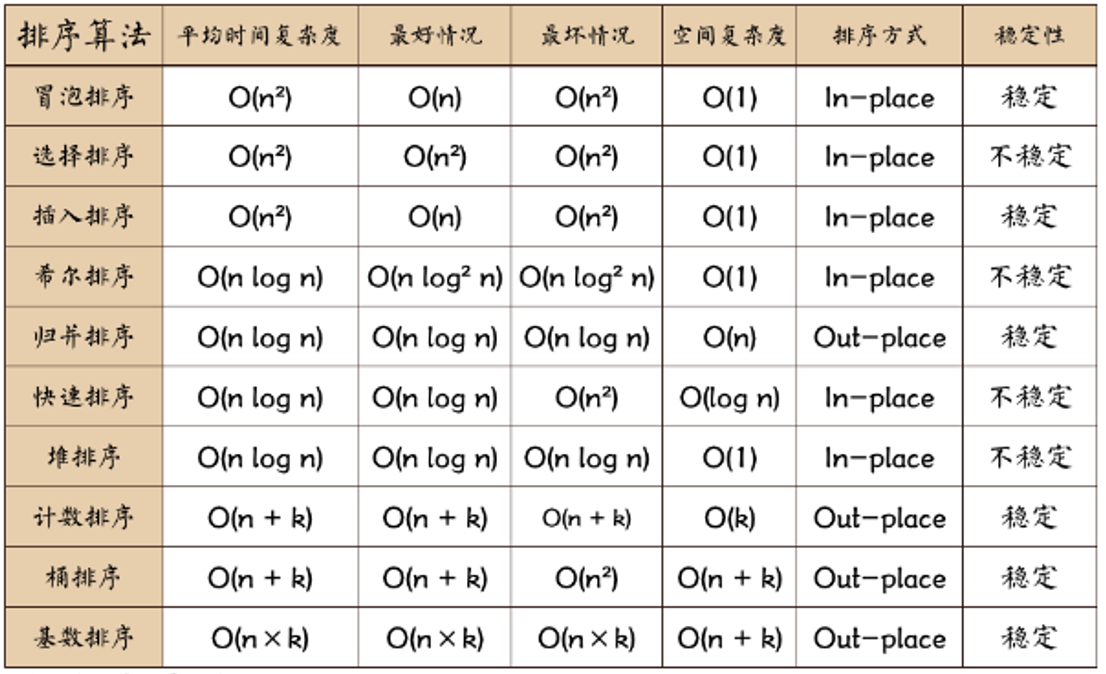
排序算法 排序:也称为排序算法
稳定性就是指排好序的相对顺序不变(比如有两个相同的数,前面那个排好后还是在前面)
不稳定:如果a原本在b的前面,而a=b,排序之后a可能会出现在b的后面;
内排序:所有排序操作都在内存中完成;
外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行;
时间复杂度:一个算法执行所耗费的时间。
空间复杂度:运行完一个程序所需内存的大小。
n: 数据规模
k: “桶”的个数
In-place: 不占用额外内存
Out-place: 占用额外内存
交换排序 冒泡排序 基本思想:通过对待排序序列从前往后,依次比较相邻元素的值,若发现逆序就立即交换,
从而让数值大的元素,逐渐从前移向后面。
未优化版冒泡排序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public static void main (String[] args) { int [] bubble = new int []{3 ,9 ,-1 ,10 ,-2 }; int temp; for (int i = 0 ;i<bubble.length-1 ;i++){ for (int j = 0 ;j<bubble.length-1 -i;j++){ if (bubble[j] > bubble[j+1 ]){ temp = bubble[j+1 ]; bubble[j+1 ] = bubble[j]; bubble[j] = temp; } } } }
优化版冒泡排序(即当发现某次排序中没有进行任何交换提前结束排序):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public static void main (String[] args) { int [] bubble = new int []{3 ,9 ,-1 ,10 ,20 }; int temp; boolean flag = false ; for (int i = 0 ;i<bubble.length-1 ;i++){ for (int j = 0 ;j<bubble.length-1 -i;j++){ if (bubble[j] > bubble[j+1 ]){ flag = true ; temp = bubble[j+1 ]; bubble[j+1 ] = bubble[j]; bubble[j] = temp; } } if (!flag){ break ; }else { flag = false ; } System.out.println("当前是第" + (i+1 ) + "次排序" ); } }
快速排序 快速排序是对冒泡排序的一种改进。
基本思想:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分
所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归
进行,以此达到整个数据变成有序序列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 public static void soft (int [] array,int left,int right) { if (left >= right){ return ; } int l = left; int r = right; int pivot = array[left]; while (l != r){ while (l < r && array[r] >= pivot){ r -= 1 ; } if (l < r){ array[l] = array[r]; } while (l < r && array[l] <= pivot){ l += 1 ; } if (l < r){ array[r] = array[l]; } } array[l] = pivot; soft(array,left,l-1 ); soft(array,l+1 ,right); }
选择排序 选择排序:是从需要排序的数据中,按指定的规则选出某一元素,再根据规则交换位置达到排序
基本思想:从一个数组的首位到末位中选出最小值,与数组首位进行交换,不断重复这个过程,最终实现排序
注意:
因此在每一轮有可能交换多次。而选择排序是通过不断遍历从开始位置到结束位置的元素,找到符合指定
的数字,但不是找到一个就交换,而是找到最后一个位置,最终达到每一轮排序只交换一次的效果。
简单选择排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public static void sort (int [] array) { int minIndex = 0 ; int min = 0 ; for (int i = 0 ; i < array.length - 1 ; i++) { minIndex = i; min = array[i]; for (int j = i+1 ; j < array.length; j++) { if (min > array[j]) { minIndex = j; min = array[j]; } } if (minIndex != i){ array[minIndex] = array[i]; array[i] = min; } } }
堆排序 堆排序:一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序。
堆是具有以下性质的完全二叉树
每个结点的值都大于或等于其左右子结点的值,称为大顶堆(对左右节点值大小的关系不做要求)
每个结点的值都小于或等于其左右子结点的值,称为小顶堆
大顶堆特点:arr[i] >= arr[2 * i+1] && arr[i] >= arr[2*i+2] // i 对应第几个节点,i从0开始编号
小顶堆:arr[i] <= arr[2 * i+1] && arr[i] <= arr[2*i+2] // i 对应第几个节点,i从0开始编号
一般升序选择将无序序列构建成大顶堆,降序将无序序列构建成小顶堆
基本思想:
1.先获取到最后一个非叶子节点(从上到下的角度),
2.让当前非叶子节点所在的树成为局部大顶堆(至于此树的左右节点大小排序则没有要求),
3.从下往上找到上一个非叶子节点,且从当前的非叶子节点从上到下进行调整为局部大顶堆
4.最后形成一个完整的大堆顶
5.再交换数组的第一个元素(堆顶)和最后一个元素(堆末),并重新构建堆结构(从新的堆顶元素开始从上往下调整)
6.最后再反复执行第5步,直至成为了一个小堆顶,此时序列已然有序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 public static void sort (int [] array) { for (int i = array.length/2 -1 ; i >= 0 ; i--) { adjustHead(array,i,array.length); } int temp = 0 ; for (int i = array.length-1 ; i >= 0 ; i--) { temp = array[i]; array[i] = array[0 ]; array[0 ] = temp; adjustHead(array,0 , i); } } public static void adjustHead (int [] array,int nodeIndex,int length) { int temp = array[nodeIndex]; for (int i = (nodeIndex*2 +1 ); i < length; i = i*2 +1 ) { if (i+1 < length && array[i] < array[i+1 ]){ i++; } if (array[i] > temp){ array[nodeIndex] = array[i]; nodeIndex = i; }else { break ; } array[nodeIndex] = temp; } }
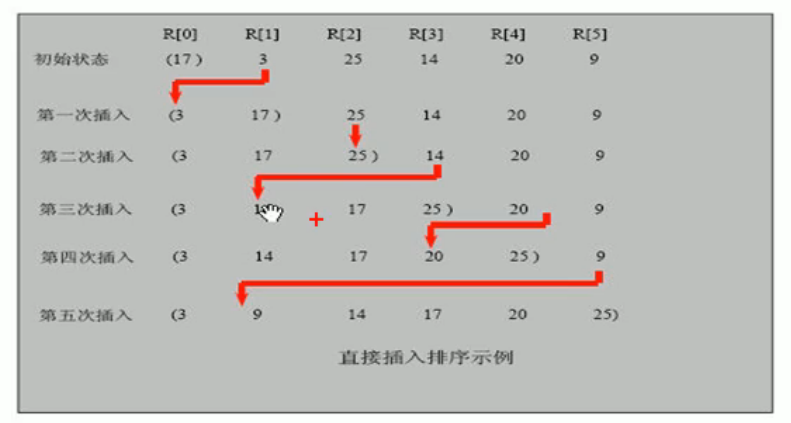
插入排序 直接插入排序 直接插入排序:将需要排序的元素以插入的方式寻找该元素的适当位置,达到排序的目的
基本思想:把n个待排序的元素看成一个有序表和一个无序表,在最开始时有序表中只有一个元素,无序表
有n-1个元素,在每次排序都会从无序表中取出第一个元素,将它的排序码与有序表元素的排序码进行比较,
将其拆入到有序表中的适当位置,从而形成新的有序表
这个排序是将大于插入值的元素后移,并遍历比较查找到插入位置后,本轮遍历结束后插入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public static void soft (int [] array) { for (int i=0 ;i< array.length-1 ;i++){ int insertVal = array[i+1 ]; int insertIndex = i; while (insertIndex >= 0 && insertVal < array[insertIndex]){ array[insertIndex + 1 ] = array[insertIndex]; insertIndex--; } array[insertIndex + 1 ] = insertVal; } } }
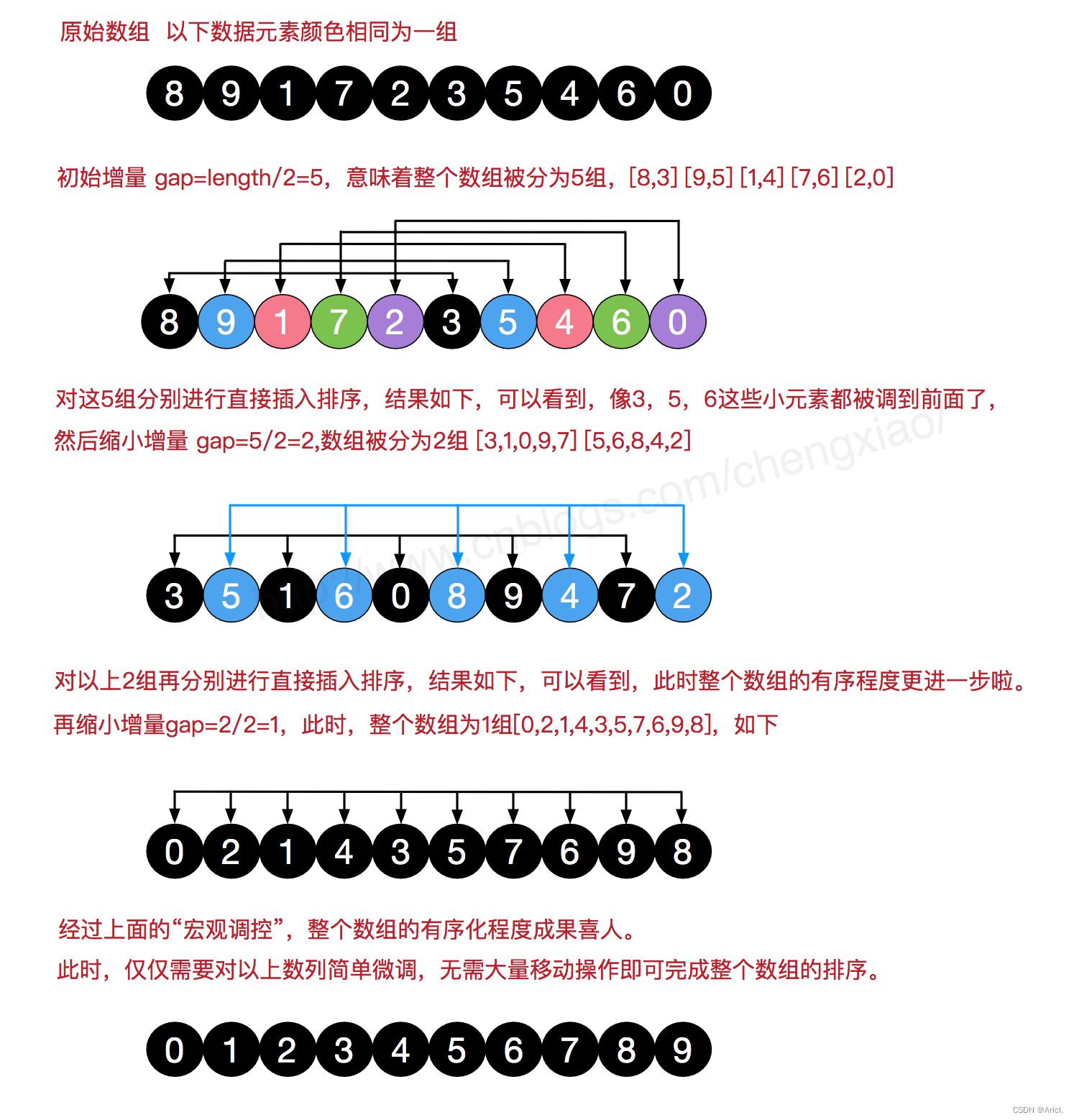
希尔排序 希尔排序:在直接插入排序的基础上经过改进的更高效排序,也被称为缩小增量排序
基本思想:把记录按照下标的一定增量分组,对每组使用直接插入排序;随着增量逐渐减少,
每组包含的关键词越来越多,当增量减至1时,整个文件刚好被分成一组,再次直接插入排序便结束排序
移位法是直接从gap增量此时的值对应下标的数开始向前比较,并判断是否需要交换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 public class ShellSortTest { public static void softShell (int [] array) { int insertIndex = 0 ; int insertVal = 0 ; for (int gap = array.length/2 ; gap > 0 ; gap /= 2 ) { for (int i = gap; i < array.length; i++) { insertIndex = i; insertVal = array[insertIndex]; if (insertVal < array[insertIndex - gap]){ while (insertIndex - gap >= 0 && insertVal < array[insertIndex - gap]){ array[insertIndex] = array[insertIndex - gap]; insertIndex -= gap; } array[insertIndex] = insertVal; } } } } public static void soft (int [] array) { int insertVal = 0 ; int gap = array.length /2 ; while (gap != 0 ) { for (int i = 0 ; i < array.length; i++) { for (int j = i + gap; j < array.length; j += gap) { insertVal = array[j]; if (array[i] > array[j]) { array[j] = array[i]; array[i] = insertVal; } } } gap = gap / 2 ; } } }
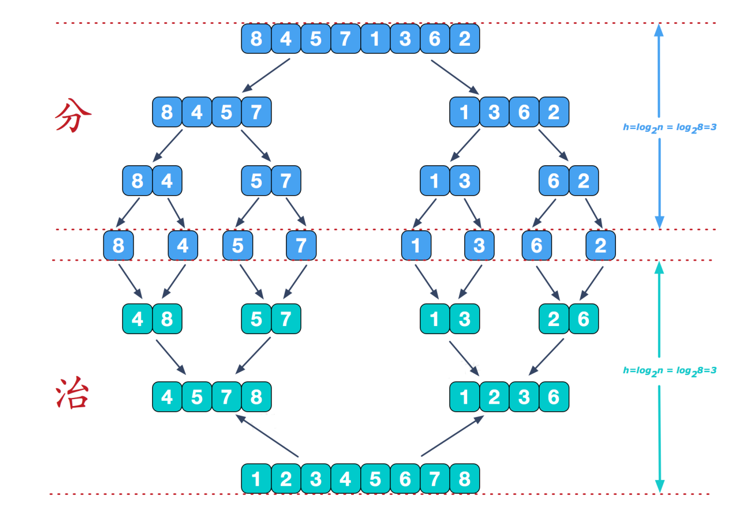
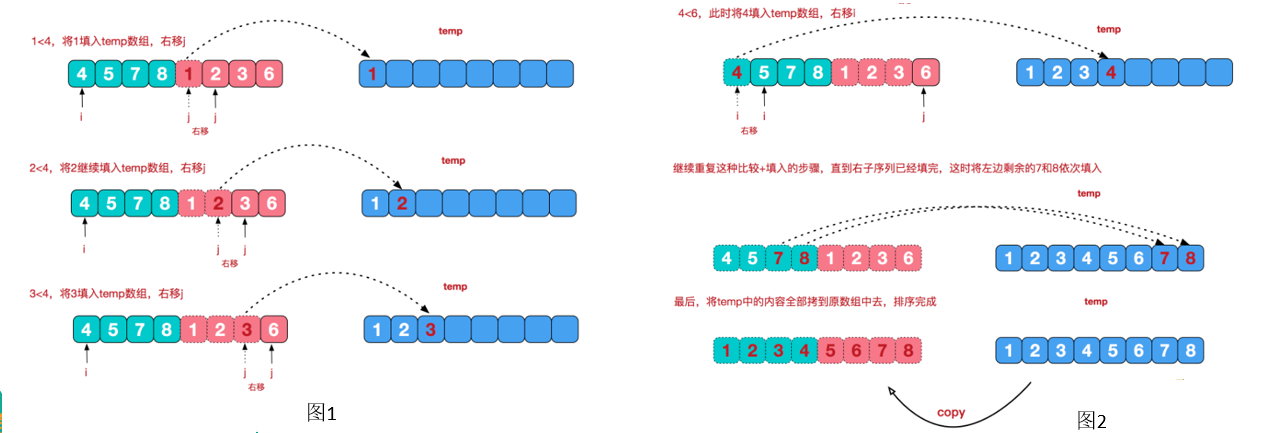
归并排序 归并排序(MERGE-SORT):利用归并的思想实现的排序,该算法采用分治(divide-and-conquer)策略
分治法将问题分成一些小的问题然后递归求解,而治的阶段则将分的阶段得到的各答案”修补”在一起
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 public class MergeSortTest { public static void mergeSoft (int [] array,int left,int right,int [] temp) { if (left >= right){ return ; } int mid = (left + right) / 2 ; mergeSoft(array,left,mid,temp); mergeSoft(array,mid+1 ,right,temp); merge(array,left,right,mid,temp); } public static void merge (int [] array,int left,int right,int mid,int [] temp) { int l = left; int m = mid + 1 ; int t = 0 ; while (l <= mid && m <= right){ if (array[l] <= array[m]){ temp[t] = array[l]; t++; l++; }else { temp[t] = array[m]; t++; m++; } } if (m-1 == right){ for (int i = l; i <= mid ; i++) { temp[t] = array[i]; t++; l++; } }else { for (int i = m; i <= right ; i++) { temp[t] = array[i]; t++; m++; } } int insertIndex = left; for (int i = 0 ; i < t; i++) { array[insertIndex] = temp[i]; insertIndex++; } } }
基数排序
基数排序是1887年赫尔曼·何乐礼发明的,属于“分配式排序”(distribution sort),又称“桶子法”(bucket sort)
基数排序(radix sort):它是通过键值的各个位的值,将要排序的元素分配至某些“桶”中,达到排序的作用。
基本思想:将整数按位数切割成不同的数字,然后按每个位数分别比较。
这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
基数排序图解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 public static void radixSoft (int [] array) { int [][] bucket = new int [10 ][array.length]; int [] bucketIndex = new int [10 ]; int max = 0 ; for (int i = 0 ; i < array.length; i++) { if (max < array[i]){ max = array[i]; } } int chuNum = 1 ; int loop = String.valueOf(max).length(); int loopNum = 0 ; while (loopNum < loop) { for (int i = 0 ; i < array.length; i++) { int num = array[i] / chuNum % 10 ; bucket[num][bucketIndex[num]] = array[i]; bucketIndex[num]++; } int index = 0 ; for (int i = 0 ; i < bucket.length; i++) { for (int j = 0 ; j < bucket[i].length; j++) { if (bucket[i][j] != 0 ){ array[index] = bucket[i][j]; index++; bucket[i][j] = 0 ; } } } chuNum *= 10 ; loopNum++; } }
查找算法 线性查找 线性查找也称为顺序查找
1 2 3 4 5 6 7 8 public static int search (int [] array,int num) { for (int i = 0 ; i < array.length; i++) { if (num == array[i]){ return i; } } return -1 ; }
二分查找 二分查找也称折半查找,二分查找的前提要求数组必须是有序的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public static int search (int [] array,int num,int left,int right) { int mid = (left + right) / 2 ; if (left > right){ return -1 ; } if (array[mid] == num) { return mid; } else if (array[mid] > num) { right = mid-1 ; return search(array, num, left, right); } else if (array[mid] < num) { left = mid+1 ; return search(array, num, left, right); } return -1 ; }
插值查找 插值查找:插值查找算法类似于二分查找,但不同的是插值查找每次是从自适应mid处开始查找
基本思想:将折半查找中的求mid 索引的公式 , low 表示左边索引left, high表示右边索引right.
key 就是要找的目标数
公式:int mid = low + (high - low) * (key - arr[low]) / (arr[high] - arr[low])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public static int search (int [] array,int left,int right,int num) { if (left > right || num < array[left] || num > array[right]){ return -1 ; } int mid = left + (right - left) * (num - array[left]) / (array[right] - array[left]); int numValue = array[mid]; if (numValue == num){ return mid; }else if (numValue > num){ right = mid - 1 ; return search(array,left,right,num); }else if (numValue < num){ left = mid + 1 ; return search(array,left,right,num); } return -1 ; }
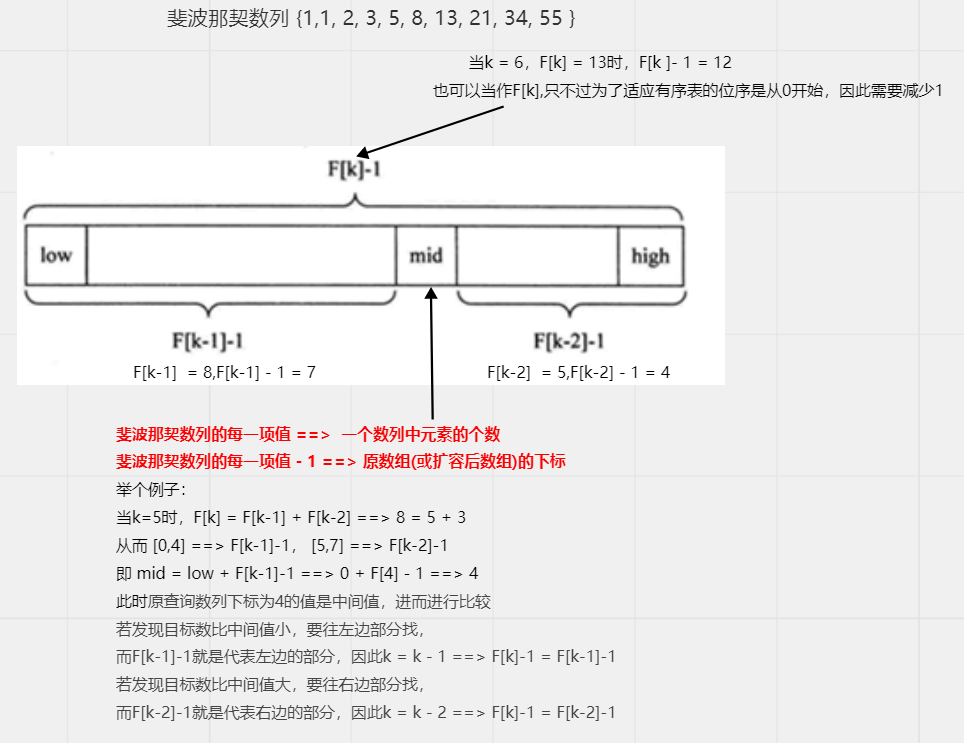
斐波那契查找 斐波那契查找也称为黄金分割法
黄金分割点是指把一条线段分割为两部分,使其中一部分与全长之比等于另一部分与这部分之比。
取其前三位数字的近似值是0.618。由于按此比例设计的造型十分美丽,因此称为黄金分割,也称为中外比
斐波那契数列即两个相邻数的比例,无限接近黄金分割值0.618
基本思想:通过改变了中间结点(mid)的位置,但mid不�再是中间或插值得到,而是位于黄金分�割点附近,
即mid=low+F(k-1)-1�(F代表斐波那契数列),通过斐波那契数组来辅助确定mid的值
由斐波那契数列 F[k]=F[k-1]+F[k-2] 的性质,可以得到(F[k]-1)=(F[k-1]-1)+(F[k-2]-1)+1,
该式说明:只要顺序表的长度为F[k]-1,则可以将该表分成长度为F[k-1]-1和F[k-2]-1的两段,
从而中间位置为mid=low+F(k-1)-1
类似的,每一子段也可以用相同的方式分割
但顺序表长度n不一定刚好等于F[k]-1,所以需要将原来的顺序表长度n增加至F[k]-1。这里的k值只要能使得
F[k]-1恰好大于或等于n即可,由以下代码得到,顺序表长度增加后,新增的位置(从n+1到F[k]-1位置),
都赋为n位置的值即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 public class FibonacciSearch { public static int maxSize = 20 ; public static int search (int [] array,int num) { int low = 0 ; int high = array.length-1 ; int k = 0 ; int mid = 0 ; int [] f = fib(); while (high >f[k]-1 ){ k++; } int [] copy = new int [0 ]; if (high <= f[k]-1 ){ copy = Arrays.copyOf(array, f[k] - 1 ); int highVal = array[high]; int tempHigh = high; int index = ++tempHigh; while (index < copy.length){ copy[index++] = highVal; } } while (low <= high) { mid = low + f[k - 1 ] - 1 ; if (copy[mid] == num) { if (mid <= high){ return mid; }else { return high; } } else if (copy[mid] > num) { high = mid - 1 ; k--; } else if (copy[mid] < num) { low = mid + 1 ; k-=2 ;; } } return -1 ; } public static int [] fib(){ int [] temp = new int [maxSize]; temp[0 ] = 1 ; temp[1 ] = 1 ; for (int i = 2 ; i < maxSize; i++) { temp[i] = temp[i-1 ] + temp[i -2 ]; } return temp; } }
赫夫曼编码
赫夫曼编码也称为哈夫曼编码(Huffman Coding)或霍夫曼编码,是一种编码方法, 属于一种程序算法
赫夫曼编码是赫哈夫曼树在电讯通信中的经典的应用之一。
赫夫曼编码广泛地用于数据文件压缩。其压缩率通常在20%~90%之间
赫夫曼码是可变字长编码(VLC)的一种,称之为最佳编码
前缀编码:字符的编码都不能是其他字符编码的前缀, 即不能匹配到重复的编码
1.根据给定的字符串统计字符串中各个字符出现的次数
2.根据字符出现的次数作为节点权值创建一个赫夫曼树
3.给各个字符设置编码(前缀编码),将这个赫夫曼树通往左边的编码设置为0,通往右边的编码设置为1
4.根据上述的字符编码将给定的字符串转换赫夫曼编码(这里实现了无损压缩)
5.经过上述操作,数据文件得到了压缩,给定字符串的长度压缩减少了60%左右。
PS:①在这个过程不会出现二义性(即某个字符编码是其他字符编码的前缀),因为每个节点都是叶子节点,
其访问的路径都是唯一的,不会重复 ②这个赫夫曼树根据排序方法不同也可能不太一样,对应的赫夫曼
编码也不完全一样,但是wpl是一样的,都是最小的, 比如: 如果我们让每次生成的新的二叉树总是排在权值
相同的二叉树的最后一个和让每次生成的新的二叉树排在权值相同的二叉树的最前面,会导致生成的两个赫
夫曼树的树排列图看起来不一样。
暂时跳过,有空再补
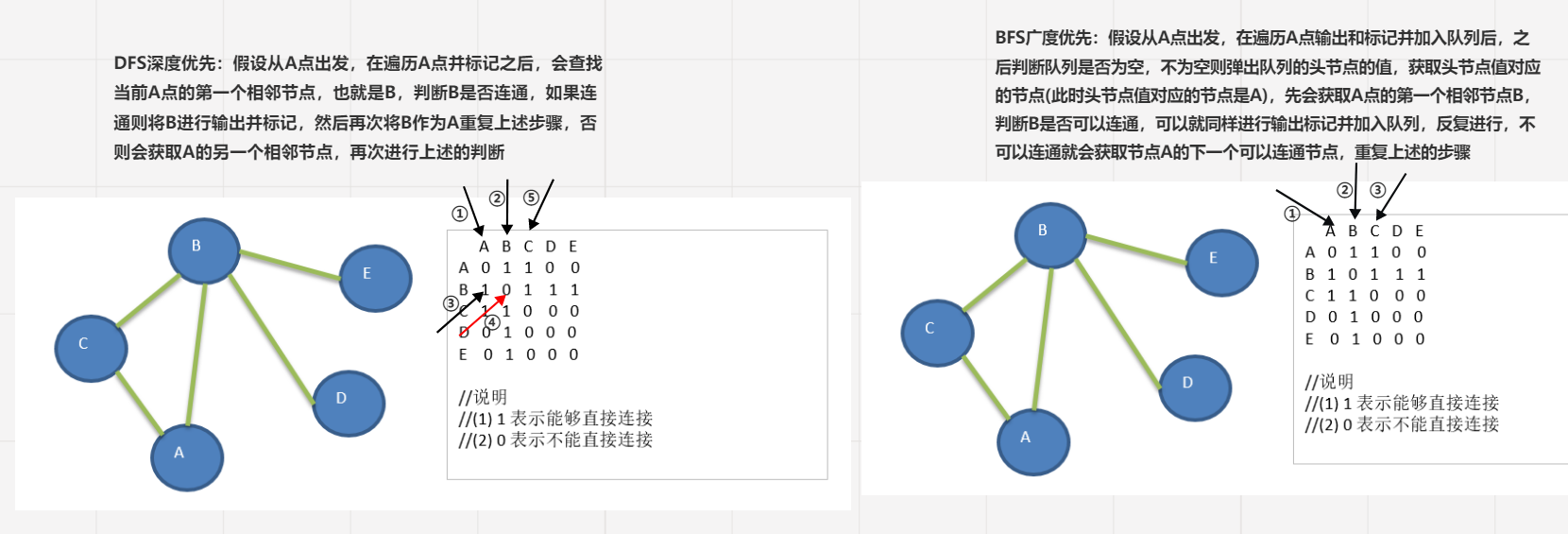
图的遍历 深度优先(DFS)
从初始结点出发,首先遍历第一个邻接结点,然后再以被遍历的邻接结点作为初始结点,
访问它的第一个邻接结点, 若发现第一个邻接结点不通,再寻求初始节点的其他相邻结点
若皆不通,则回退到刚刚访问过的节点寻找它的相邻节点,不断循环,直至遍历结束。
换句话来说就是 一条路走到黑为止
①遍历初始节点 标记为已遍历
②得到初始节点的第一个相邻节点
判断第一个相邻节点的情况
Ⅰ判断是否存在(不存在,返回到刚刚访问过的节点寻找它的相邻节点)
Ⅱ判断是否已被遍历(已遍历,返回到刚刚访问过的节点寻找它的相邻节点)
③以当前的相邻节点作为初始节点重复以上步骤
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 public int getFirstNearVertex (int index) { for (int i = 0 ; i < vertexList.size(); i++) { if (edges[index][i] != 0 ){ return i; } } return -1 ; } public int getNextNearVertex (int indexRow,int indexColumn) { for (int i = indexColumn+1 ; i < vertexList.size(); i++) { if (edges[indexRow][i] != 0 ){ return i; } } return -1 ; } public void dfs (int index) { String v = getVertexOfValue(index); System.out.println(v); beReadVertex[index] = true ; int w = getFirstNearVertex(index); while (w != -1 ){ if (!beReadVertex[w]){ dfs(w); } w = getNextNearVertex(index,w); } } public void dfs () { for (int i = 0 ; i < vertexList.size(); i++) { if (!beReadVertex[i]){ dfs(i); } } }
广度优先(BFS)
类似于一个分层搜索的过程,广度优先遍历需要使用一个队列以保持访问过的结点的顺序,
以便按这个顺序来访问这些结点的邻接结点。换句话来说广度优先就是先将某一行的能够
访问的节点先全部遍历,有点类似树的层序遍历
①先创建队列
②输出下标对应节点并标记为已遍历同时将当前节点入队列
③判断队列是否为空
不为空弹出当前队列的头节点并找到对应下标的节点
④找到当前队列头节点下标值的相邻节点
⑤判断相邻节点是否存在
Ⅰ如果存在再判断是否已被遍历
Ⅱ尚未遍历则输出当前节点并标记为已遍历,同时加入队列中
Ⅲ再次寻找当前头节点下标值对应节点其他能够连通但尚未遍历的节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 public void bfs (int index) { LinkedList<Integer> queue = new LinkedList <>(); System.out.print(getVertexOfValue(index) + "=>" ); beReadVertex[index] = true ; queue.add(index); int u; int w; while (!queue.isEmpty()){ if (beReadVertex[beReadVertex.length-1 ]){ return ; } u = queue.poll(); w = getFirstNearVertex(u); while (w != -1 ){ if (!beReadVertex[w]){ System.out.print(getVertexOfValue(w) + "=>" ); beReadVertex[w] = true ; queue.add(w); } w = getNextNearVertex(u,w); } } } public void bfs () { for (int i = 0 ; i < vertexList.size(); i++) { if (!beReadVertex[i]){ bfs(i); } } }
DFS与BFS的区别 ①DFS深度优先更倾向于纵向遍历,而BFS更倾向于横向遍历
②DFS一般使用栈和回溯来实现,BFS一般使用队列来实现
③DFS占用的空间较小,BFS占用的空间较大
常用算法 二分查找(非递归) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public static int binarySearch (int [] array,int num) { int start = 0 ; int end = array.length-1 ; while (start <= end){ int middle = (start+end)/2 ; if (num == array[middle]) { return middle; }else if (num > array[middle]){ start = middle + 1 ; } else if (num < array[middle]) { end = middle - 1 ; } } return -1 ; }
分治算法 分治算法的基本思想:将某个具有一定规模的大问题通过一定的方式分解成多个小问题,通过解决多个
小问题从而找到解决这个大问题的方案。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public static void hanoiTower (int num,char a,char b,char c) { if (num == 1 ){ System.out.println("第1个盘,从 " + a + " => " + c ); }else { hanoiTower(num - 1 ,a,c,b); System.out.println("第" + num + "个盘,从 " + a + " => " + c); hanoiTower(num - 1 ,b,a,c); } }
动态规划
什么是动态规划(Dynamic Programming)算法
这个算法的核心思想就是将大问题划分为小问题进行解决,从而一步步获取最优解的处理算法
与分治法不同的是,适合于用动态规划求解的问题,经分解得到子问题往往不是互相独立的。
( 即下一个子阶段的求解是建立在上一个子阶段的解的基础上,进行进一步的求解 )
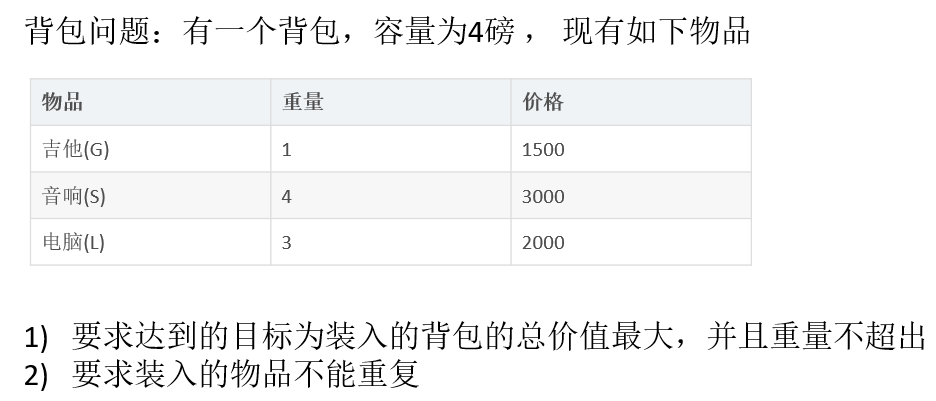
背包问题是指给一个定容量的背包及若干个一定价值和重量的物品,如何选择物品放入背包使物品的价值最大。
其中又分01背包(每种物品最多放一个)和完全背包(完全背包指的是:每种物品可以无限件放入)
而无限背包可以转化为01背包。
实现思路:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 public static void main (String[] args) { int [] weight = {1 ,4 ,3 }; int [] value = {1500 ,3000 ,2000 }; int m = 4 ; int n = value.length; int [][] dp = new int [n+1 ][m+1 ]; int [][] path = new int [n+1 ][m+1 ]; for (int i = 0 ; i <= dp.length; i++) { dp[0 ][i] = 0 ; } for (int i = 0 ; i < dp.length; i++) { dp[i][0 ] = 0 ; } for (int i = 1 ; i < dp.length; i++) { for (int j = 1 ; j < dp[i].length; j++) { if (weight[i-1 ] > j){ dp[i][j] = dp[i-1 ][j]; }else { if (dp[i-1 ][j] < value[i-1 ]+dp[i-1 ][j-weight[i-1 ]]){ dp[i][j] = value[i-1 ]+dp[i-1 ][j-weight[i-1 ]]; path[i][j] = 1 ; }else { dp[i][j] = dp[i-1 ][j]; } } } } int i = path.length - 1 ; int j = path[0 ].length - 1 ; while (i > 0 && j > 0 ){ if (path[i][j] == 1 ){ System.out.printf("第%d个物品放入背包中\n" ,i); j -= weight[i-1 ]; } i--; } for (int [] d : dp) { for (int ii : d) { System.out.print(ii + "\t" ); } System.out.println(); } }
KMP算法
常用于在一个文本串S内查找一个模式串P的出现位置。
Knuth-Morris-Pratt 也称为字符串查找算法,简称为 “KMP算法”。
此算法由Donald Knuth、Vaughan Pratt、James H. Morris三人发表,故取这3人的姓氏命名此算法。
通过将模式串和文本串转为char型数组进行逐一匹配,失败则回溯到匹配前的下一个字符再次执行前序步骤
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public static int violenceMatch (String matchStr,String str) { char [] matchChar = matchStr.toCharArray(); char [] strChar = str.toCharArray(); int i = 0 ; int j = 0 ; while (i < matchChar.length && j < strChar.length){ if (matchChar[i] == strChar[j]){ i++; j++; }else { i = i - j + 1 ; j = 0 ; } } if (j == strChar.length){ return i-j; }else { return -1 ; } }
KMP算法利用之前判断过信息,通过一个next数组,保存模式串中前后最长公共子序列的长度,
每次回溯时,通过next数组找到,前面匹配过的位置,省去了大量的计算时间
根据模式串的前缀得出各个下标对应的最长公共前后缀的长度,从而根据这些长度值形成前缀表
将前缀表整体右移(舍弃右边最高位),首位补-1形成了next数组,当文本串和模式串逐一匹配时,
当出现第一个失配位(两个串的字符不同)时,假设失配位为i,根据模式串中i下标对应的最长公共
前后缀的长度x,将模式串第x位数对准文本串中的当前i的失配位处,重新进行比较,反正进行
上述步骤,直至找到一组完成匹配。
KMP字符串查找算法核心就是 模式串 => 前缀表 => next数组 => 文本串和模式串借助next数组不断匹配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 public static int kmpMatch (String textStr,String modelStr) { char [] text = textStr.toCharArray(); char [] model = modelStr.toCharArray(); int [] next = getNextInt(modelStr); int i = 0 ; int j = 0 ; while (i < text.length && j < model.length){ if (text[i] == model[j]){ i++; j++; }else { j = next[j]; if (j == -1 ){ i += 1 ; j = 0 ; } } } if (j == model.length){ return i-j; }else { return -1 ; } } public static int [] getNextInt(String modelStr){ char [] str = modelStr.toCharArray(); int [] prefixTable = new int [modelStr.length()]; int i = 1 ; int len = 0 ; while (i < str.length){ if (str[i] == str[len]){ len++; prefixTable[i] = len; }else { len = 0 ; prefixTable[i] = 0 ; } i++; } int [] next = new int [str.length]; next[0 ] = -1 ; for (int j = 1 ; j < next.length; j++) { next[j] = prefixTable[j-1 ]; } return next; }
贪心算法
贪婪算法(贪心算法)是指在对问题进行求解时,在每一步选择中都采取最好或者最优(即最有利)的选择,
从而希望能够导致结果是最好或者最优的算法,它所得到的结果不一定是最优的结果(有时候会是最优解),
但是都是相对近似(接近)最优解的结果。
贪心算法并不从整体最优上加以考虑,它所做的选择只是在某种意义上的局部最优解。
实现思路:
①将所有待覆盖地区全部加入一个集合areaList
②用一个集合selectList记录所选择的电台
③针对每个电台进行遍历,计算其能够覆盖的地区数,每一轮选择最多覆盖数的电台,
将此电台加入selectList,同时将此电台所覆盖的所有地区从areaList集合中去除。
④不断重复第③步,直至areaList集合的长度为0,此时代表已经完成对所有地区的覆盖。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 public static List<String> greedy () { HashMap<String, String[]> broadcasts = new HashMap <>(); broadcasts.put("k1" ,new String []{"北京" , "上海" , "天津" }); broadcasts.put("k2" ,new String []{"广州" , "北京" , "深圳" }); broadcasts.put("k3" ,new String []{"成都" , "上海" , "杭州" }); broadcasts.put("k4" ,new String []{"上海" , "天津" }); broadcasts.put("k5" ,new String []{"杭州" , "大连" }); HashSet<String> areaList = new HashSet <>(); Collection<String[]> areaNames = broadcasts.values(); for (String[] name : areaNames){ Collections.addAll(areaList, name); } List<String> selectList = new ArrayList <>(); String maxBCIndex = "" ; while (areaList.size() != 0 ){ int max = 0 ; Set<String> broadcastName = broadcasts.keySet(); for (String bcName : broadcastName) { int needCoverNum = 0 ; String[] coverAreaArray = broadcasts.get(bcName); for (String area : coverAreaArray){ if (areaList.contains(area)){ needCoverNum++; } } if (needCoverNum != 0 ){ if (max < needCoverNum){ max = needCoverNum; maxBCIndex = bcName; } } } selectList.add(maxBCIndex); String[] broadcast = broadcasts.get(maxBCIndex); for (String areaName : broadcast){ areaList.remove(areaName); } broadcasts.remove(maxBCIndex); } return selectList; }
①动态规划类似于穷举法,记录了之前的结果,不需要进行重复的计算,可以利用前边的结果(状态方程),
一般复杂度比贪心高,但是可以得到全局最优解。
②贪心算法每次只考虑当前,不保证能得到全局最优,只保证当前最优,都是先选择再证明,一般复杂度比较低。
③贪心算法的基本要素:最优子结构性质和贪心选择性质
动态规划的基本要素:最优子结构性质和重叠子问题性质
④动态规划算法通常以自底向上的方式解各子问题,而贪心算法则通常自顶向下的方式进行。
自底向上:换句话理解说就是从小到大,通过不断解决小问题从而解决原问题
自顶向下:换句话理解就是从原问题入手,通过不断分解成小问题,从而解决原问题
⑤贪心算法每次都将问题分解成一个子问题,再将所有子问题的解进行融合,从而解决原问题。
动态规划将计算过程中的结果保存下来重复使用,避免无必要的重复计算。
未完待续~剩下内容,有机会再补充。












 稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面;
稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面;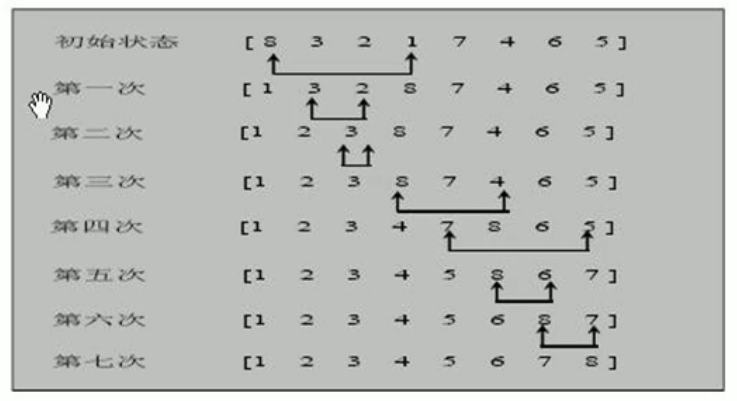



 wechat
wechat alipay
alipay



