
Volatile关键字
现代计算机的内存模型
实早期计算机中cpu和内存的速度是差不多的,但在现代计算机中,cpu的指令速度远超内存的存取速度,由于计算机的存储设备与处理器的运算速度有几个数量级的
差距,所以现代计算机系统都不得不加入一层读写速度尽可能接近处理器运算速度的高速缓存(Cache)来作为内存与处理器之间的缓冲。
将运算需要使用到的数据复制到缓存中,让运算能快速进行,当运算结束后再从缓存同步回内存之中,这样处理器就无须等待缓慢的内存读写了。
基于高速缓存的存储交互很好地解决了处理器与内存的速度矛盾,但是也为计算机系统带来更高的复杂度,因为它引入了一个新的问题:缓存一致性(CacheCoherence)。
在多处理器系统中,每个处理器都有自己的高速缓存,而它们又共享同一主内存(MainMemory)。
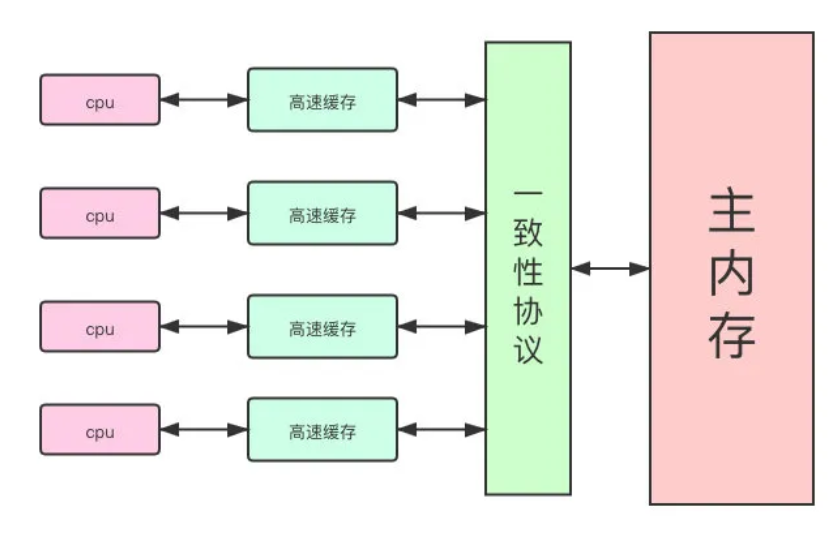
JMM
Java内存模型(JavaMemoryModel)描述了Java程序中各种变量(线程共享变量)的访问规则,以及在JVM中将变量,存储到内存和从内存中读取变量这样的底层细
节。
- 本地内存和主内存的关系:
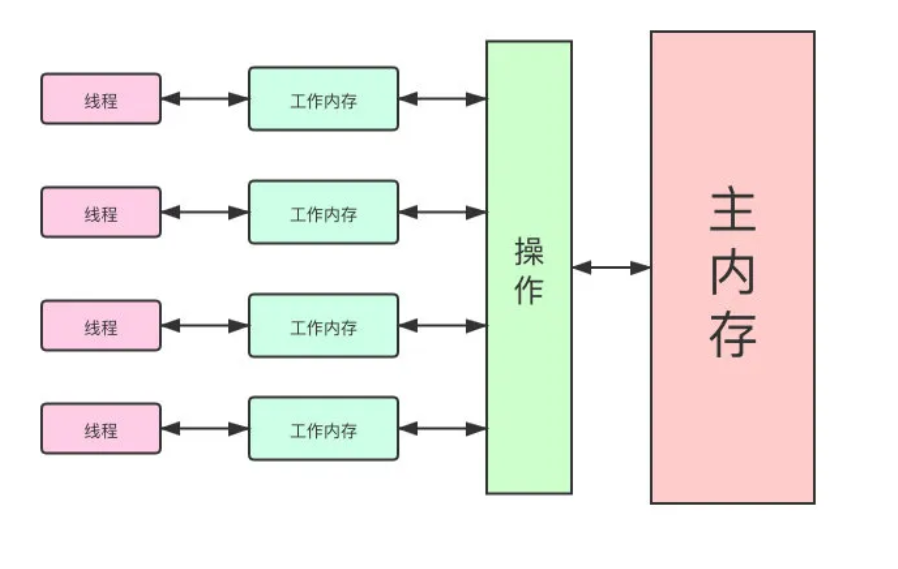
数据的可见性
数据的可见性:当一个数据出现变化后,其他地方获取的数据与修改后的数据保持一致。
1.加锁(synchornized或者lock)能保证数据可见性的原因:
①在获得锁后的线程,会先将自己的工作内存清空,从主内存中读取并复制自己要操作的共享变量的副本
②在操作完成后,会把工作内存中的共享变量的新值对主内存中的共享变量的旧值进行覆盖,最后释放锁
③因为在synchornized和lock修饰的内部线程都是单线程,没有获得锁的其余线程都处于阻塞状态,也就保证了数据的可见性
2.Volatile关键字是如何保证数据的可见性的?
当一个实例变量或全局变量被Volatile修饰时,当一个线程对这些变量进行修改时,新值就会被立即强制写入到主内存中,
同时让其他的线程工作内存中的这些变量副本的缓存全部失效,当其他线程发现缓存已经失效了,就会到主内存中重新获取新值,
因此也就保证了数据的可见性。
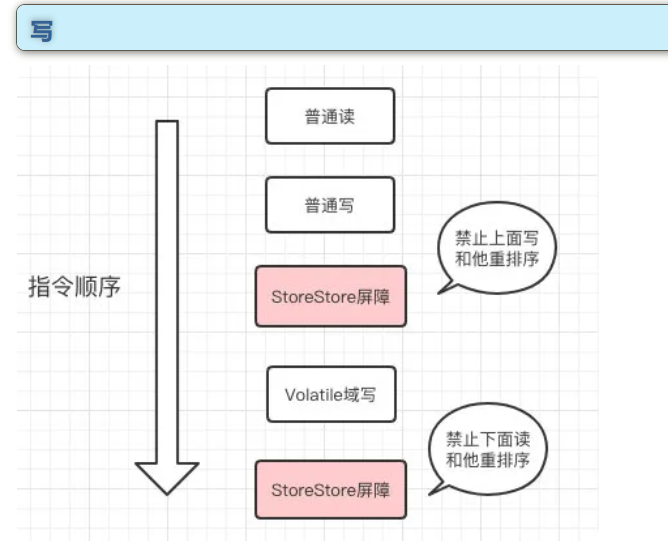
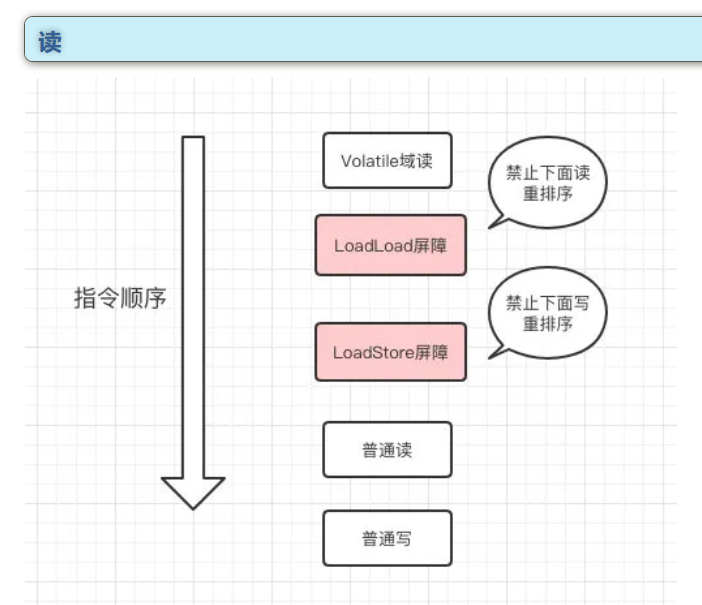
禁止指令重排序
在JMM的设定中会针对编译器制定volatile重排序规则:
- 在volatile的写操作前后,分别添加1个内存屏障阻止了指令的重排序
- 在volatile的读操作后面,添加2个内存屏障阻止了指令的重排序
单例模式双重检查
使用volatile可以在单例模式中实现可见性和禁止指令重排序。
以创建对象为例,对象实际上创建对象要进过如下几个步骤:
①分配内存空间。
②调用构造器,初始化实例。
③返回地址给引用
在这个过程中是可能发生指令重排序的,例如构造函数在对象初始化完成前就赋值完成了,在内存里面开辟了一片存储区域后直接返回内存的引用,
这个时候还没真正的初始化完对象,对象的值还是为null的。而别的线程此刻去判断instance!=null,就会导致空指针的异常。
可见性得到保证是因为volatile修改的变量会让此变量在其他线程工作内存中的副本失效,必须重新读取主内存的值
原子性问题
在对基本数据类型(除了long和double类型的)的读取和赋值的过程中都是原子性的,即不会有任何指令能插入。
而volailte是修饰共享变量(实例变量和类变量),因此是没有原子性的
volatile与synchronized的区别
volatile只能修饰实例变量和类变量,而synchronized可以修饰方法,以及代码块。
volatile保证数据的可见性,但是不保证原子性(多线程进行写操作,不保证线程安全);而synchronized是一种排他(互斥)的机制。
volatile用于禁止指令重排序:可以解决单例双重检查对象初始化代码执行乱序问题。
volatile可以看做是轻量版的synchronized,volatile不保证原子性,但是如果是对一个共享变量进行多个线程的赋值,而没有其他的操
作,那么就可以用volatile来代替synchronized,因为赋值本身是有原子性的,而volatile又保证了可见性,所以就可以保证线程安全了。
 wechat
wechat alipay
alipay




