
MySQL基础
初识数据库
持久化:将数据保存到可掉电式存储设备中。
作用:将内存中的数据存储在关系型数据库中,也可是磁盘文件或XML数据文件
DB:数据库(Database)
存储数据的“仓库”,相当于为存储数据的文件夹
DBMS:数据库管理系统(Database Management System)
管理和操作数据库的大型软件,可理解为一个软件
SQL:结构化查询语言(Structured Query Language)
用于于数据库通信的语言,理解为对数据库数据的一种增删改查的手段
常见数据库
Oracle甲骨文
Oracle 2 —-RDBMS(关系型数据库管理系统)
Oracle —> BEA Systems —> SUN公司 —> MySQL
MySQL
①开放源代码的关系型数据库管理系统
②32位系统表文件最大支持4GB,64位系统支持最大的表文件8TB
SQL Server
微软开发的大型商业数据库
DB2
IBM公司,用于银行系统
PostgreSQL
简称PgSQL,是开源的
SyBase
提供了数据建模 PowerDesigner
SQLite
嵌入式小型数据库,应用在手机端
informix
IBM公司,运用于unix和linux平台
关系型数据库(RDBMS)
最古老的数据库类型,将数据结构变为了简单的二维关系
以“行(row)“ 和 “列(column)” 的形式存储数据 —-> 一行一列构成了表(table) —-> 一组表形成一个库 (datebase)
表与表之间数据记录有关系,关系型数据库即建立在关系模型基础上的数据库
优势
①可进行复杂查询:用SQL语句在多个表之间进行复杂的数据查询
②事务支持:实现对安全性能较高的数据访问
非关系型数据库(非RDBMS)
可以理解为阉割版的RDBMS,舍弃部分功能以提高查询性能
非RDBMS的数据库类型
①键值型数据库:经常用于内存缓存。主流的是Redis键值型数据库
②文档型数据库:用于存储并获取数据,例如XML、JSON等格式
③搜索引擎数据库:核心原理是”倒排索引“,对全文索引效率较低。主流:Solr、Elasticsearch、Splunk等
④列式数据库:大量降低系统的I/O,适合分布式文件系统。主流:HBase。
⑤图形数据库:经常用于刻画对象之间的关系。主流:Neo4J、InfoGrid
关系型数据库的设计规则
数据库的典型结构是数据表,一个数据库可以有多张表,每张表都有一个名字,而表名具有唯一性
- E-R(entity-relationship,实体-练习)的模型主要概念:实体集、属性、联系集
ORM(Object Relation Mapping)对象关系映射:
表table <—> (实体集)类class 行(row) <—> (实体)类的对象Instance 列(column) <—> (字段)类中的属性field
表的关联关系
4种关系:一对一关联‘、一对多关联、多对多关联、自我引用
SQL语言
SQL语言的分类
DDL(Data Definition Languages)数据定义语言
CREATE(创建) \ ALTER(修改) \ DROP(删除) \ RENAME(重命名) \TRUNCATE(清空)
DML(Data Manipulation Language)数据操作语言
INSERT (添加) \ DELETE(删除) \ UPDATE(更改) \ SELECT(查询)
DCL(Data Control Language)数据控制语言
GRANT(赋予权限) \ REVOKE(回收权限) \ COMMIT(提交) \ ROLLBACK(回滚) \ SAVEPOINT(保存点)
- SELECT查询语句使用频率较高,因此其又被独称一类:DQL(Date Query Language数据查询语言)
- 还有将 COMMIT 、 ROLLBACK 两者共称为TCL (Transaction Control Language,事务控制语言)
SQL语言的规则与规范
- 每条命令以 ; 或 \g 或 \G 结束
- 关键字都是大写的,不能缩写,也不能分行
SQL大小写不同环境区别
MySQL 在 Windows 环境下是大小写不敏感的
MySQL 在 Linux 环境下是大小写敏感的
- 数据库名、表名、表的别名、变量名是严格区分大小写的
- 关键字、函数名、列名(或字段名)、列的别名(字段的别名) 是忽略大小写的。
推荐采用统一的书写规范:
- 数据库名、表名、表别名、字段名、字段别名等都小写
- SQL 关键字、函数名、绑定变量等都大写
补充:在SQL中字符串用单引号,列的别名用双引号
注释
- 单行注释:#注释文字(MySQL特有的方式)
- 单行注释:– 注释文字(–后面必须包含一个空格。)
- 多行注释:/* 注释文字 */
- 补充 导入数据库的方式:①source 文件的全路径 ②利用图形化界面的工具
基本的SELECT语句
- SELECT
SELECT 字段1,字段2 FROM 表名
SELECT * FROM 表名;//* 表中的所有字段(或列)
查询字段返回的结果称为结果集
列的别名
创建类的别名的方式
①列名后空格 起名
②as(别名) :alias
③使用一对“ ”包起来;
补充:列的别名只能在关键字ORDER BY中使用,不能在WHERE中使用
1 | SELECT employee_id emp_id,last_name AS lname,department_id "部门id" |
去重关键字:distinct
空值参与运算
①空值:null,其参与运算的结果都为空(null)
②null 不等同于0或者‘null’,仅仅只是说明不确定有没有 比如奖金为0是没有 奖金为null是不确定有没有
1 | #空值参与运算 |
着重号 ``
作用:当数据库名或表名与关键字、保留字相同时,使用着重号``表示输入的是表名或数据库名
查询常数
数据的每一行都会添加此常数(不一定在此表中存在)
下面的‘北京市’即为常数
1 | #查询常数 |
显示表结构
关键字:describe
DESCRIBE 表名;
过滤数据
关键字:where ,需要声明在from的后面
使用注意:字符串需要使用一对’ ‘修饰,与Java的字符串有所区别
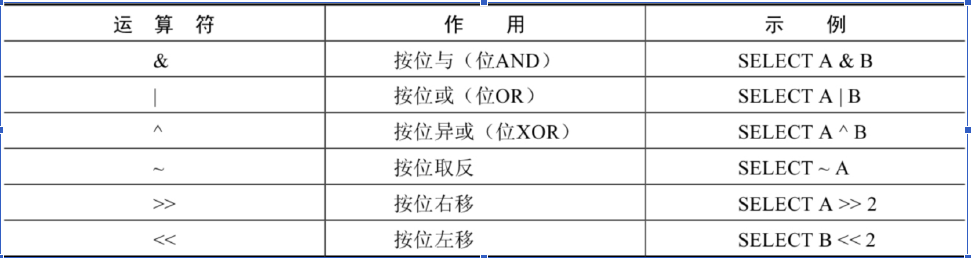
运算符
算术运算符
/(DIV) 都表示除法运算:div 和 /的区别:
整数 DIV 整数 = 整数 例如 100 DIV 3 = 33;
整数 / 整数 = 取商的整数部分+默认保留小数点后四位 例如: 100 / 3 = 33.3333
%(MOD):
在SQL中,+ 号没有连接的作用,仅仅表示加法运算
1 | #在java中为1001,这里的‘1’ 和 java中的“1”是一样的 因为sql中字符串是以 ‘ ’ 修饰的 |
比较运算符
符号:=(等于)、<=>(安全等于)、<>或!=(均是不等于)、
判断都是true,则返回1;判断都是false,则返回0,其余情况返回null
特殊的:<=>安全等于是为区别 null的情况,两个数值都为null返回1;其中一个为null返回0
规则;
- 字符串存在隐式转换,如果转换数值不成功,则默认当成0
- 两边都是字符串的花,则按照ANSI的比较规则进行比较
- 只要有null 参与判断,结果就为null;
1 | #对应第一种 |
相关关键字
is null(为空) \ is not null(不为空) \ isnull类似一个方法== WHERE ISNULL(commission_pct);
least(value1,value2) :取两者中小的输出 \ greatest(value1,value2):取两者中大的输出
between 条件下限1 and 条件上限2 (查询条件1和条件2范围内的数据,包括条件1、2其本身的数据)
in(set):查询是set集合数值的数据信息 \not in(set):查询不是set集合数值的数据信息
like():模糊查询 % :代表不确定个数的字符(0个,1个,多个) _ :代表一个不确定的字符 转义字符:\
正则表达式运算符:regexp \ rlike :
| 正则表达式 |
|---|
| (1)‘^’匹配以该字符后面的字符开头的字符串。 |
| (2)‘$’匹配以该字符前面的字符结尾的字符串。 |
| (3)‘.’匹配任何一个单字符。 |
| (4)“[…]”匹配在方括号内的任何字符。例如,“[abc]”匹配“a”或“b”或“c”。为了命名字符的范围,使用一 个‘-’。“[a-z]”匹配任何字母,而“[0-9]”匹配任何数字。 |
| (5)‘’匹配零个或多个在它前面的字符。例如,“x”匹配任何数量的‘x’字符,“[0-9]”匹配任何数量的数字, 而“”匹配任何数量的任何字符。 |
逻辑运算符
符号:XOR(逻辑异或):取满足一真一假的结果、OR(||)、AND(&&)、!(NOT)
补充:OR可以和AND一起使用,但由于AND的优先级高于OR,因此先 对AND两边的操作数进行操作,再与OR中的操作数结合。
位运算符
取反从底层二进制是从最高位逐个取反
排序与分页
排序
如果没有使用任何排序操作,默认情况下查询返回的数据是按照添加数据的顺序显示的
使用关键字ORDER BY 进行排序操作
升序:asc(ascend);从低到高
降序:desc(descend);从高到低
一般在 ORDER BY 字段 后面没有显示的声明使用哪种排序方式,则默认使用的是升序排列
补充:列的别名只能在关键字中使用,不能在WHERE中使用
1 | #降序:desc(descend);从高到低 |
分页
使用关键字LIMIT实现数据的分页操作
格式: LIMIT:LIMIT位置偏移量,条目数
在一定情况下,”LIMIT 0,条目数“ == ”LIMIT 条目数“
运用公式:LIMIT(pageNO - 1) * pageSize,pageSize;
WHERE … ORDER BY … LIMIT 声明顺序如下
1 | SELECT department_id,salary,last_name |
- MySQL8.0新特性:LIMIT … OFFSET … ;
在8.0与5.7有明显的区别 LIMIT 条目数 OFFSET LIMIT位置偏移量.;
多表查询
多张表写成一张表会造成冗余、多IO、事务方面锁定的影响
笛卡尔积(交叉连接)现象
多表查询中笛卡尔积的错误现象:是指一张表中的数据在另一个表中全都匹配了一次——原因是:缺少了连接条件
正确的查询操作:注(在查询语句中如果存在多个表有相同的字段,则必须指明此字段所在的表
为了增加sql语句的可读性,可以考虑给表起别名,但是在之后的在select和where中必须使用别名,不能使用表的原名
1 | #SQL92的写法 |
结论:如果有n个表进行多表的的查询,则至少需要n-1个连接条件
1 | SELECT emp.`employee_id`,emp.`last_name`,dep.`department_name`,loc.`city` |
多表查询的分类
等值连接 与 非等值连接
等值连接:连接条件使用等于= 的连接
非等值连接:连接条件不使用等于= 的连接,包括!=!、>、<等
自连接 与 非自连接
自连接 :同一张表的查询连接
非自连接:不是同一张表的查询连接
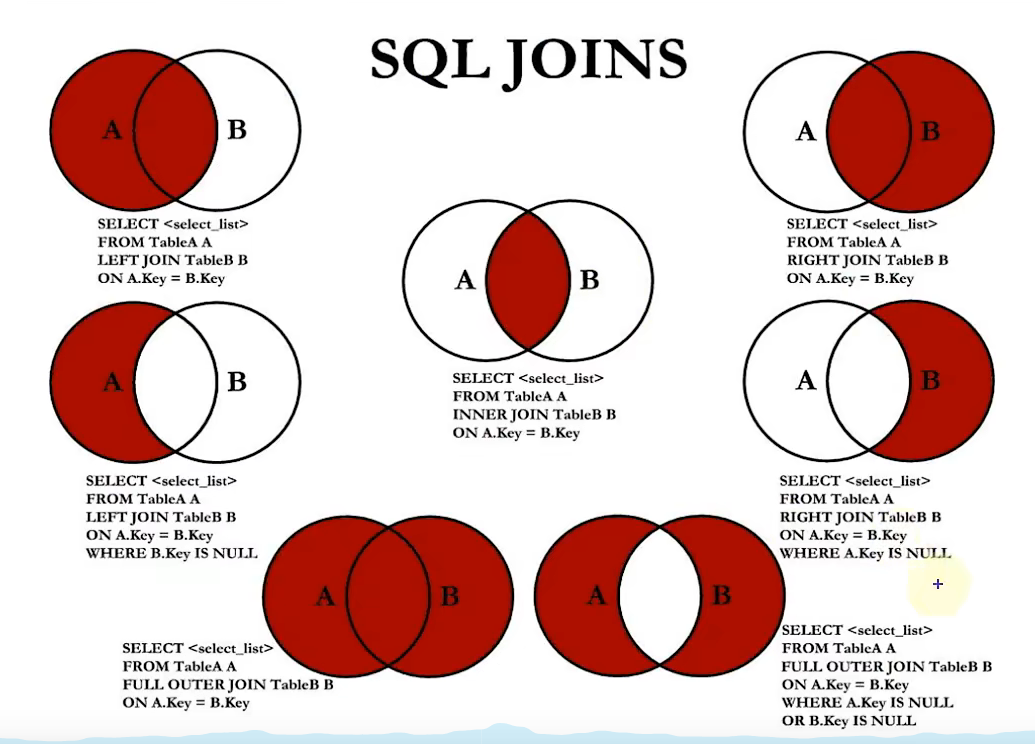
内连接 与 外连接
- 内连接:查询返回的结果集只包含符合条件的行,结果集中不包含一个表与另一个表不匹配的行
举个例子:
1 | #SQL92语法实现的内连接 |
2. 外连接:查询返回的结果集只包含符合条件的行,结果集中除了包含一个表与另一个表匹配的行以外,还包括左表 和 右表中不匹配的行
外连接的分类:左外连接(符合匹配结果集以及左表不满足的行)
右外连接(符合匹配结果集以及右表不满足的行)
满外连接(符合匹配结果集以及左表、右表不满足的行)
SQL92语法实现内连接:见上方例子代码
SQL92语法实现外连接:使用 + 号 ————但在MySQL中不支持此写法
SQL99语法实现多表查询:JOIN … ON的方式——MySQL支持此写法
1 | #sql99语法实现内连接 |
7种JOIN的方式
注针对左外或者右外只取其中左表活右表的数据:
此时左外连接相当于左边数据比右边数据长,因此右边需要补一个null值,而左中图是只要左表不匹配的数据
也就是说此时类似交集部分的右表的值不是空的,因此过滤条件是只要右表为null的
右中图反着来,同个道理,在此不做说明
1 | #sql99语法 |
UNION关键字
- UNION:返回两个查询结果集的并集,去除重复部分
- UNION ALL :返回两个查询结果集的并集,对于重复部分,不去除
一般来说,尽量选择使用UNION ALL,相对于UNION来说UNION ALL 效率更高,因为不涉及去重
举个例子:1 ; 106 ; 16
UNION返回的结果是1+106+16,UNION ALL返回的结果是1+106+106+16
SQL99语法新特性(了解)
自然连接:NATURAL JOIN
可以理解为SQL92语法种等值连接,一般会自动查询两张连接表的所有相同字段并给予返回字符集,但是不够灵活
USING的使用
不适用于自连接
可以理解为NATURAL JOIN的改良版,可以查询返回指定的相同字段的字符集
1 | #自然连接 |
函数
不同的DBMS之间关于函数的定义的差异远大于同个语言种的不同版本
内置函数 自定义函数
单行函数
概念:只对一行进行变换,每行只返回一个结果,且可以进行嵌套,参数可以为某一列或者一个字符串
数值函数
- 基本函数-
| ABS(x) 返回x的绝对值 |
|---|
| SIGN(X)返回X的符号。正数返回1,负数返回-1,0返回0 |
| PI() 返回圆周率的值 |
| CEIL(x),CEILING(x) 返回大于或等于某个值的最小整数 |
| FLOOR(x) 返回小于或等于某个值的最大整数 |
| LEAST(e1,e2,e3…) 返回列表中的最小值 |
| GREATEST(e1,e2,e3…) 返回列表中的最大值 |
| MOD(x,y) 返回X除以Y后的余数 |
| RAND() 返回0~1的随机值 |
| RAND(x) 返回0~1的随机值,其中x的值用作种子值,相同的X值会产生相同的随机 数 |
| ROUND(x) 返回一个对x的值进行四舍五入后,最接近于X的整数 |
|---|
| ROUND(x,y) 返回一个对x的值进行四舍五入后最接近X的值,并保留到小数点后面Y位 |
| TRUNCATE(x,y) 返回数字x截断为y位小数的结果 |
| SQRT(x) 返回x的平方根。当X的值为负数时,返回NULL |
- 角度 与 弧度 转换
RADIANS(x) 将角度转化为弧度,其中,参数x为角度值
DEGREES(x) 将弧度转化为角度,其中,参数x为弧度值
- 三角函数
| SIN(x) 返回x的正弦值,其中,参数x为弧度值 |
|---|
| ASIN(x) 返回x的反正弦值,即获取正弦为x的值。如果x的值不在-1到1之间,则返回NULL |
| COS(x) 返回x的余弦值,其中,参数x为弧度值 |
| ACOS(x) 返回x的反余弦值,即获取余弦为x的值。如果x的值不在-1到1之间,则返回NULL |
| TAN(x) 返回x的正切值,其中,参数x为弧度值 |
| ATAN(x) 返回x的反正切值,即返回正切值为x的值 |
| ATAN2(m,n) 返回两个参数的反正切值 |
| COT(x) 返回x的余切值,其中,X为弧度值 |
- 指数与对数
| POW(x,y),POWER(X,Y) 返回x的y次方 |
|---|
| EXP(X) 返回e的X次方,其中e是一个常数,2.718281828459045 |
| LOG(X) 返回以e为底的X的对数,当X <= 0 时,返回的结果为NULL |
| LN(X),LOG10(X) 返回以10为底的X的对数,当X <= 0 时,返回的结果为NULL |
| LOG2(X) 返回以2为底的X的对数,当X <= 0 时,返回NULL |
- 进制转换
| BIN(x) 返回x的二进制编码 |
|---|
| HEX(x) 返回x的十六进制编码 |
| OCT(x) 返回x的八进制编码 |
| CONV(x,f1,f2) 返回f1进制数变成f2进制数 |
字符串函数-
注意:MySQL中,字符串的位置是从1开始的。
1 | /* |
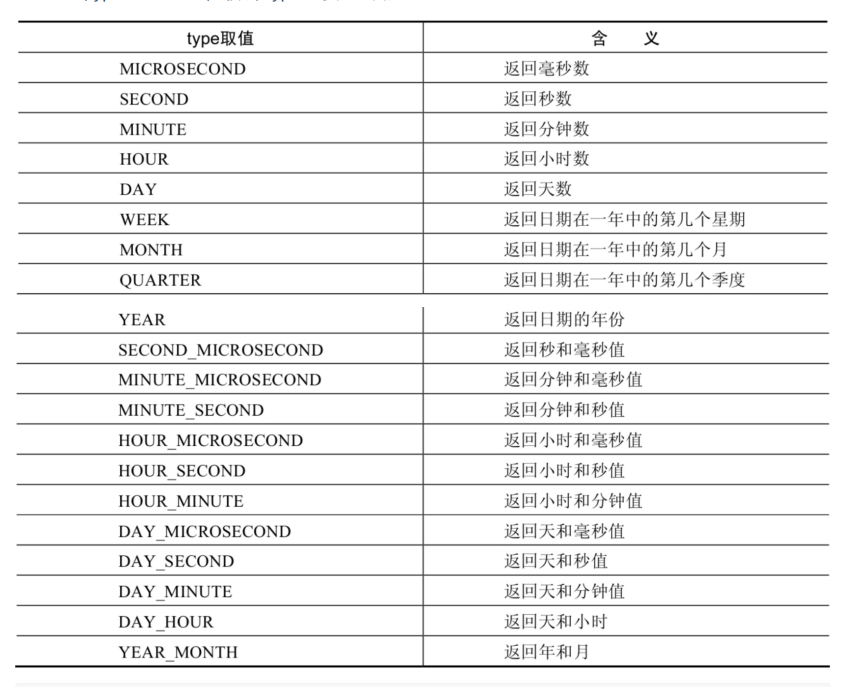
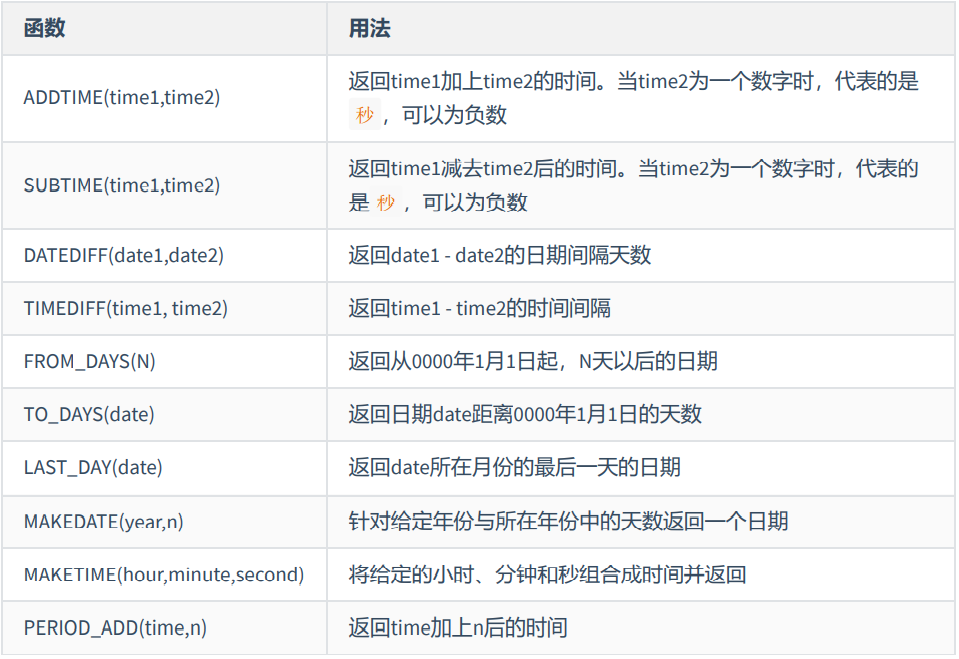
日期和时间函数
- 获取日期、时间-
| CURDATE() ,CURRENT_DATE() 返回当前日期,只包含年、 月、日 |
|---|
| CURTIME() , CURRENT_TIME() 返回当前时间,只包含时、 分、秒 |
| NOW() / SYSDATE() / CURRENT_TIMESTAMP() / LOCALTIME() / LOCALTIMESTAMP() 返回当前系统日期和时间 |
- 日期与时间戳的转换-
| UNIX_TIMESTAMP() 以UNIX时间戳的形式返回当前时间。SELECT UNIX_TIMESTAMP() - >1634348884 |
|---|
| UNIX_TIMESTAMP(date) 将时间date以UNIX时间戳的形式返回。 |
| FROM_UNIXTIME(timestamp) 将UNIX时间戳的时间转换为普通格式的时间 |
- 获取月份、星期、星期天、天数等函数
| YEAR(date) / MONTH(date) / DAY(date) 返回具体的日期值 |
|---|
| HOUR(time) / MINUTE(time) / SECOND(time) 返回具体的时间值 |
| MONTHNAME(date) 返回月份:January,… |
| DAYNAME(date) 返回星期几:MONDAY,TUESDAY…..SUNDAY |
| WEEKDAY(date) 返回周几,注意,周1是0,周2是1,。。。周日是6 |
| QUARTER(date) 返回日期对应的季度,范围为1~4 |
| WEEK(date) , WEEKOFYEAR(date) 返回一年中的第几周 |
| DAYOFYEAR(date) 返回日期是一年中的第几天 |
| DAYOFMONTH(date) 返回日期位于所在月份的第几天 |
| DAYOFWEEK(date) 返回周几,注意:周日是1,周一是2,。。。周六是7 |
- 日期的操作函数
| EXTRACT(type FROM date) 返回指定日期中特定的部分,type指定返回的值 |
|---|
- 时间和秒钟转换的函数
| TIME_TO_SEC(time) 将 time 转化为秒并返回结果值。转化的公式为: 小时*3600+分钟 *60+秒 |
|---|
| SEC_TO_TIME(seconds) 将 seconds 描述转化为包含小时、分钟和秒的时间 |
- 日期和时间函数的计算-
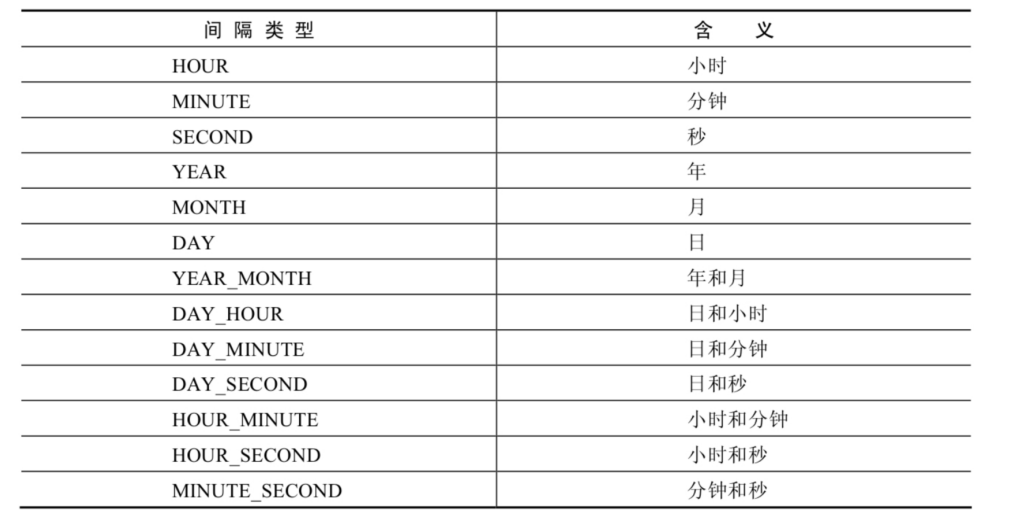
| DATE_ADD(datetime, INTERVAL expr type), ADDDATE(date,INTERVAL expr type) 返回与给定日期时间相差INTERVAL时 间段的日期时间 |
|---|
| DATE_SUB(date,INTERVAL expr type), SUBDATE(date,INTERVAL expr type) 返回与date相差INTERVAL时间间隔的 日期 |
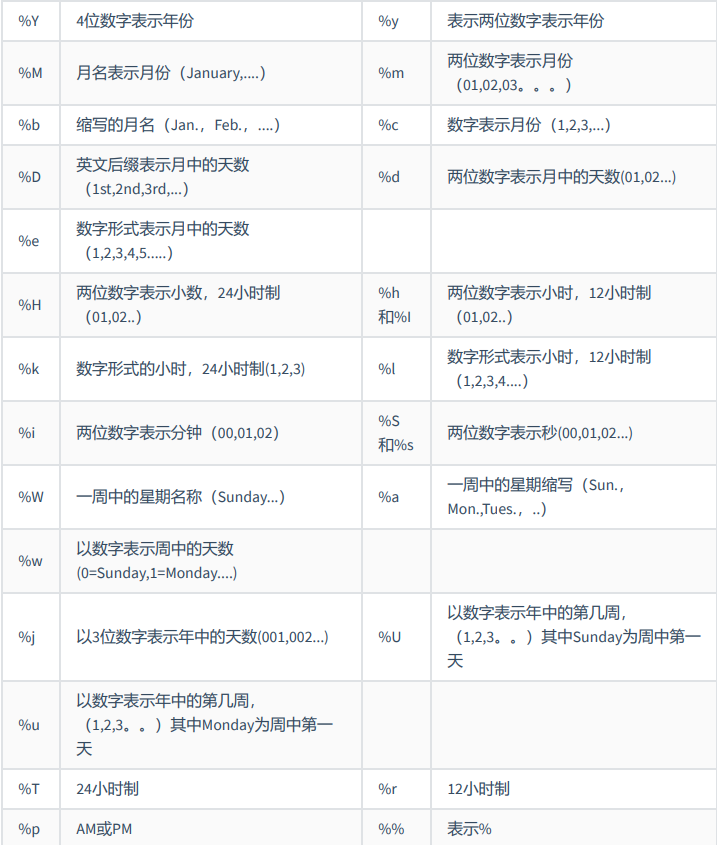
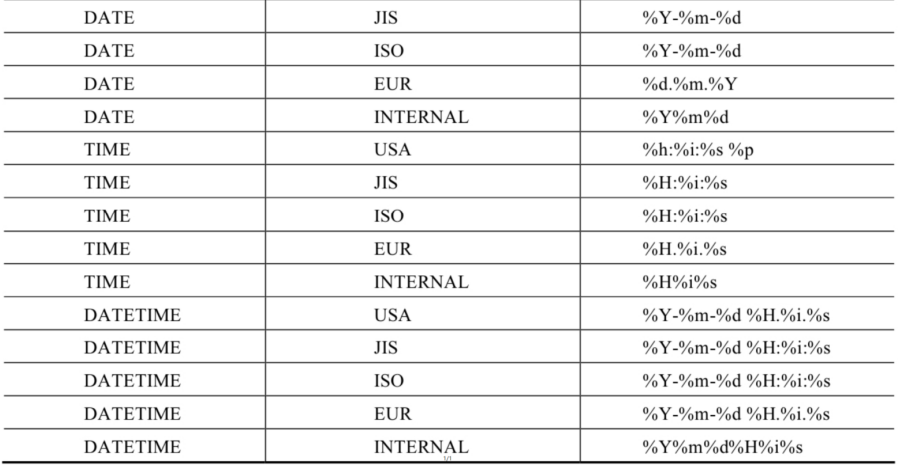
- 日期的格式化与解析-
| DATE_FORMAT(date,fmt) 按照字符串fmt格式化日期date值 |
|---|
| TIME_FORMAT(time,fmt) 按照字符串fmt格式化时间time值 |
| GET_FORMAT(date_type,format_type) 返回日期字符串的显示格式 |
| STR_TO_DATE(str, fmt) 按照字符串fmt对str进行解析,解析为一个日期 |

流程控制函数
流程处理函数可以根据不同的条件,执行不同的处理流程
当条件是有范围的,考虑使用case WHEN
当条件是具体的某个字段,考虑使用case- expr WHEN
| IF(value,value1,value2) 如果value的值为TRUE,返回value1, 否则返回value2 |
|---|
| IFNULL(value1, value2) 如果value1不为NULL,返回value1,否 则返回value2 |
| CASE WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2 …. [ELSE resultn] END 相当于Java的if…else if…else… |
| CASE expr WHEN 常量值1 THEN 值1 WHEN 常量值1 THEN 值1 …. [ELSE 值n] END 相当于Java的switch…case… |
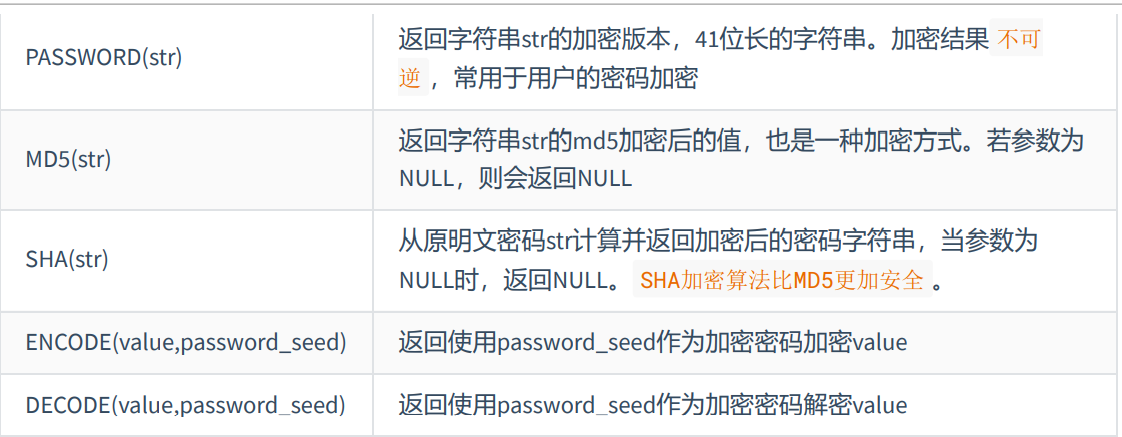
加密与解密函数
(了解)
password(str)、encode()、decode()在MySQL8.0中被弃用
MySQL信息函数
(了解)
| VERSION() 返回当前MySQL的版本号 |
|---|
| CONNECTION_ID() 返回当前MySQL服务器的连接数 |
| DATABASE(),SCHEMA() 返回MySQL命令行当前所在的数据库 |
| USER(),CURRENT_USER()、SYSTEM_USER(), SESSION_USER() 返回当前连接MySQL的用户名,返回结果格式为 “主机名@用户名 |
| CHARSET(value) 返回字符串value自变量的字符集 |
| COLLATION(value) 返回字符串value的比较规则 |
其他函数
(了解)
对于FORMAT(value,n)的函数:如果n的值小于或者等于0,则只保留整数部分
| FORMAT(value,n) 返回对数字value进行格式化后的结果数据。n表示 四舍五入 后保留 到小数点后n位 |
|---|
| CONV(value,from,to) 将value的值进行不同进制之间的转换 |
| INET_ATON(ipvalue) 将以点分隔的IP地址转化为一个数字 |
| INET_NTOA(value) 将数字形式的IP地址转化为以点分隔的IP地址 |
| BENCHMARK(n,expr) 将表达式expr重复执行n次。用于测试MySQL处理expr表达式所耗费 的时间 |
| CONVERT(value USING char_code) 将value所使用的字符编码修改为char_code |
多行函数(聚合函数)
聚合函数作用于一组数据,并对一组数据最终只会返回一个值
- 常见的聚合函数
- AVG / SUM(只适用于数值类型的字段或变量)
1 | SELECT AVG(salary),SUM(salary) |
- MAX / MIN(适用于数值类型、字符串类型、日期时间类型的字段或变量)
1 | #MAX / MIN |
COUNT
作用:计算指定字段在查询结构中出现的个数,不包含null
计算表中有多少条数据的方式 公式AVG = SUM / COUNT
①COUNT(*)
②COUNT(1);相当于每遍历一行就标记一个1,最终统计标记了多少个1,内部填2也是同个结果
③COUNT(具体字段);不一定完全正确,count统计的只是不为null的行,有些字段中数据为null,count不统计在内
补充:在统计表中的记录数方面
如果使用的是MyISAM 存储引擎,这三个的效率都是相同的,都是O(1)
但如果使用的是InnoDB 存储引擎,则效率就不同:COUNT(*) = COUNT(1) > COUNT(具体字段)
- GROUP BY的使用
①在SELECT中出现的非组函数的字段必须声明在GROUP BY中,而在GROUP BY中声明的字段则不一定需要出现在SELECT中
②GROUP BY 声明在FROM 和 WHERE后面,ORDER BY 和 LIMIT 的前面
③(了解)MySQL中GROUP BY中使用 WITH ROLLUP
在使用ROLLUP 后,不能同时使用ORDER BY 关键字进行排序,ROLLUP 和 ORDER BY 是相互排斥的,造成报错
1 | #查询各个department_id,job_id的平均工资 |
- Having的使用
作用:用来过滤数据
①如果过滤条件使用了聚合函数,则必须使用HAVING来替代WHERE,否则,报错
②HAVING必须声明在 GROUP BY 的后面
补充:一般在MySQL中使用HAVING 的前提是已经 使用了 GROUP BY ,
否则 意义不大,GROUP BY的结果是多条的,HAVING 起过滤作用,少了GROUP BY结果只有一条也就没必要进行过滤了
1 | #Having的使用 |
针对代码块内的查询练习:当过滤条件中有聚合函数时,则此过滤条件必须声明在HAVING中
当过滤条件中没有聚合函数时,过滤条件声明在哪都可以,但声明在WHERE中为好,其效率较高
HAVING 与 WHERE 的比较
①在适用范围上,Having的适用范围上更广
②在过滤条件没有聚合函数,此时where的效率要更高
where先连接后筛选,数据更小;havaing则是先筛选后连接
- SQL底层执行原理
1 | /* |
SQL语句执行的先后顺序
FROM … , …–> ON –>(LEFT / RIGHT) JOIN … –> WHERE –> GROUP BY–> HAVING –>SELECT –> DISTINCT –> ORDER BY –> LIMIT
不相关子查询
分为:外查询(主查询) 内查询(子查询)
注意事项:
- 子查询要包括在括号内
- 一般将子查询放在比较条件右侧,可读性更好
- 单行操作符对于单行子查询,多行操作符对应多行子查询
子查询的分类
①从内查询的返回的结果的条目数
单行子查询 和 多行子查询
②内查询是否被执行多次
相关子查询 和 不相关子查询
可以理解为不相关子查询返回的结果类型是固定,而相关子查询还要根据主查询的数据进行一定的判断,从而造成被执行多次
单行子查询
单行比较操作符:比较特殊的一个 <> 此操作符是不等于
①单行子查询中的空值问题:子查询如果返回null(子查询不返回任何行),即找不到,而主查询就会出现字段空白的情况
②非法使用子查询:子查询中返回了多行数据,但主查询使用了单行比较符
多行子查询
多行比较操作符
| IN 等于列表中的任意一个 |
|---|
| ANY 需要和单行比较操作符一起使用,和子查询返回的某一个值比较 |
| ALL 需要和单行比较操作符一起使用,和子查询返回的所有值比较 |
| SOME 实际上是ANY的别名,作用相同,一般常使用ANY |
在使用IN 或者 NOT IN 的位置通常可以考虑使用EXISTS 与 NOT EXISTS 代替
①多行子查询中的空值问题:
1 | #空值问题 |
子查询嵌套例题
1 | #10.查询平均工资最高的 job 信息 |
相关子查询
在SELECT中,除了GROUP BY 和 LIMIT 之外,其他位置都可以声明子查询!
EXISTS 与 NOT EXISTS关键字
EXISTS 子查询 找到的提交 / NOT EXISTS 子查询中 找不到的提交
关联子查询通常也会和 EXISTS操作符一起来使用,用来检查在子查询中是否存在满足条件的行。
如果在子查询中不存在满足条件的行:
- 条件返回 FALSE 继续在子查询中查找
如果在子查询中存在满足条件的行 :
不在子查询中继续查找 条件返回 TRUE
NOT EXISTS关键字表示如果不存在某种条件,则返回TRUE,否则返回FALSE。
1 | #使用IN |
创建和管理
从系统架构的层次上看,MySQL 数据库系统从大到小依次是 数据库服务器 、 数据库 、 数据表 、数据表的 行与列 。
标识符命名规则
数据库名、表名不得超过30个字符,变量名限制为29个
必须只能包含 A–Z, a–z, 0–9, _共63个字符 数据库名、表名、字段名等对象名中间不要包含空格
同一个MySQL软件中,数据库不能同名;同一个库中,表不能重名;
同一个表中,字段不能重名 必须保证你的字段没有和保留字、数据库系统或常用方法冲突。如果坚持使用,请在SQL语句中使 用`(着重号)引起来
保持字段名和类型的一致性:在命名字段并为其指定数据类型的时候一定要保证一致性,假如数据 类型在一个表里是整数,那在另一个表里可就别变成字符型了
数据库 的创建与管理
- 创建数据库的方式
方式一 :使用默认字符集创建
CREATE DATABASE 数据库名方式二 :显式指明创建数据库所用的字符集
CREATE DATABASE 数据库名 CHARACTER SET ‘GBK’
方式三 :如果创建的数据库已经存在,则创建失败,但不报错 (推荐方式)
CREATE DATABASE IF NOT EXISTS 数据库名 CHARACTER SET ‘GBK’
- 数据库的管理
查看当前连接中所有的数据库:show database
指定使用某个数据库:use database
查看当前连接数据库的表:show tables
查看当前使用的数据库:select database() from dual
查看指定数据下的表:show tables from 数据库名
查看已创建的数据库结构 :show create database 数据库名
查看表的结构:desc 数据表名
- 修改数据库
更改数据库的字符集:ALTER DATABASE 数据库名 CHARACTER SET 字符集; #比如:gbk、utf8等
删除数据库
方式一:DROP DATABASE 数据库名;
方式二:如果要删除的数据库不存在,则删除失败,但不报错 (推荐方式)
DROP DATABASE IF EXISTS 数据库名
数据表 的创建和管理
创建数据表的方式
①方式一:使用VARCHAR来定义字符串时,必须在使用VARCHAR时指明其长度
如果创建表时没有使用指定的字符集,则默认使用表所在的数据库的字符集
1 | CREATE TABLE IF NOT EXISTS test_tab ( |
②方式二:基于现有的表
1 | CREATE TABLE test_table |
- 修改数据表 ALTER TABLE
1 | #①添加字段 |
- 重命名数据表
1 | #方式一(推荐使用) |
删除数据表
将表的结构和表的数据一起删除,释放表的空间
DROP TABLE IF EXISTS test_t;
清空数据表
清空表中的所有数据,但表的结构还保留
TRUNCATE TABLE employees_copy;
DCL、DDL、DML
DCL中的 commit 和 rollback
commit:提交数据。(数据保存在数据库中,数据不支持回滚)
rollback:回滚数据。(执行此关键字实现数据的回滚,回滚到最近的一次COMMIT之后)
TRUNCATE TABLE 与 DELETE FROM
TRUNCATE TABLE:执行此操作,会将表的数据全部清除,且数据是不支持回滚的
DELETE FROM :执行此操作,表数据也会全部清除,但可以选择性的清除部分数据。且其数据是可以实现回滚的
补:TRUNCATE TABLE要比DELETE FROM要快,因其不需要考虑数据备份的问题,所以使用的系统和事务日志资源少,
但也正是如此,使用TRUNCATE有可能造成事故,如一小心误删核心数据而无法恢复,DELETE 则可以避免这个问题
DDL 与 DML
以DDL 与 DML为首执行的区别
①DDL的操作一旦执行,就不可以回滚。且指令SET autocommit = FALSE 对DDL的操作无效
在每次DDL执行完成之后都会自动执行一次COMMIT,且此COMMIT是不受上述指令的影响
②DML的操作在默认情况下,一旦执行也是不可回滚的,
但如果在执行之前,曾执行过 指令SET autocommit = FALSE ,则此时的操作是可回滚的
DML的增删改
无论是添加、更新、删除的操作都有可能会因为约束的作用导致操作失败
DML默认情况下,执行完以后都会commit自动提交数据,
如果不希望其自动提交数据需要使用 指令 SET autocommit = FALSE。
添加数据
- 方式一:一条一条的添加数据
1 | #单条逐个添加 |
- 方式二:将查询结果插入表中
1 | INSERT INTO the_table(id,the_name,salary,hire_date) |
补充说明:the_table表中要添加数据的字段的长度不能小于employees表中查询的字段长度,否则有添加失败的可能
更新数据
使用的格式:UPDATE … SET … WHERE
在where 添加条件 可以实现批量修改的功能
1 | #将表中id为5的hire_date设为当前系统时间 |
删除数据
使用的格式:DELETE FROM … WHERE
1 | DELETE FROM the_table |
MySQL8 新特性:计算列
计算列:某一列的值是通过别的列计算得来的
例如:a列值为1,b列值为2,c列的值定义为 a+b ,则c列称为计算列
1 | CREATE TABLE test1( |
MySQL的数据类型
写在前头,一般在定义数据类型,确定是整数,使用INT;确定是小数,使用DECIMAY(M精度,D标度);确定是日期和时间,使用DATETIME;
虽然存储空间占用变大了,但是数据的安全和可靠性得到了一定的保证
整数类型(整形)
整数类型一共有 5 种,包括 TINYINT、SMALLINT、MEDIUMINT、INT(INTEGER)和 BIGINT
| 整数类型 | 字节 | 有符号数取值范围 | 无符号数取值范围 |
|---|---|---|---|
| TINYINT | 1 | -128~127 | 0~255 |
| SMALLINT | 2 | -32768~32767 | 0~65535 |
| MEDIUMINT | 3 | -8388608~8388607 | 0~16777215 |
| INT、INTEGER | 4 | -2147483648~2147483647 | 0~4294967295 |
| BIGINT | 8 | -9223372036854775808~9223372036854775807 | 0~18446744073709551615 |
在mysql 5.7中 desc table 所显示的字段类型后面括号内的数实际上是 数据的显示宽度,但在MySQL 8.0中已经不考虑使用。
ZEROFILL:当insert的值不足5位时,使用0填充 ②当使用ZEROFILL,自动添加UNSIGNED
UNSIGNED : 无符号类型(非负),默认是正数。int类型默认显示宽度为int(11),无符号int类型默认显示宽度为int(10)。

- mysql 5.7的演示
1 | CREATE TABLE test_int1( |
TINYINT :一般用于枚举数据,比如系统设定取值范围很小且固定的场景。
SMALLINT :可以用于较小范围的统计数据,比如统计工厂的固定资产库存数量等。
MEDIUMINT :用于较大整数的计算,比如车站每日的客流量等。
INT、INTEGER :取值范围足够大,一般情况下不用考虑超限问题,用得最多。比如商品编号。
BIGINT :只有当你处理特别巨大的整数时才会用到。比如双十一的交易量、大型门户网站点击量、证 券公司衍生产品持仓等。
浮点类型
浮点数和定点数类型的特点是可以 处理小数
MySQL支持的浮点数类型,分别是 FLOAT、DOUBLE、REAL。
float表示单精度浮点数,double表示双精度浮点数,read默认是double,除非使用“ REAL_AS_FLOAT ”将read改为默认float
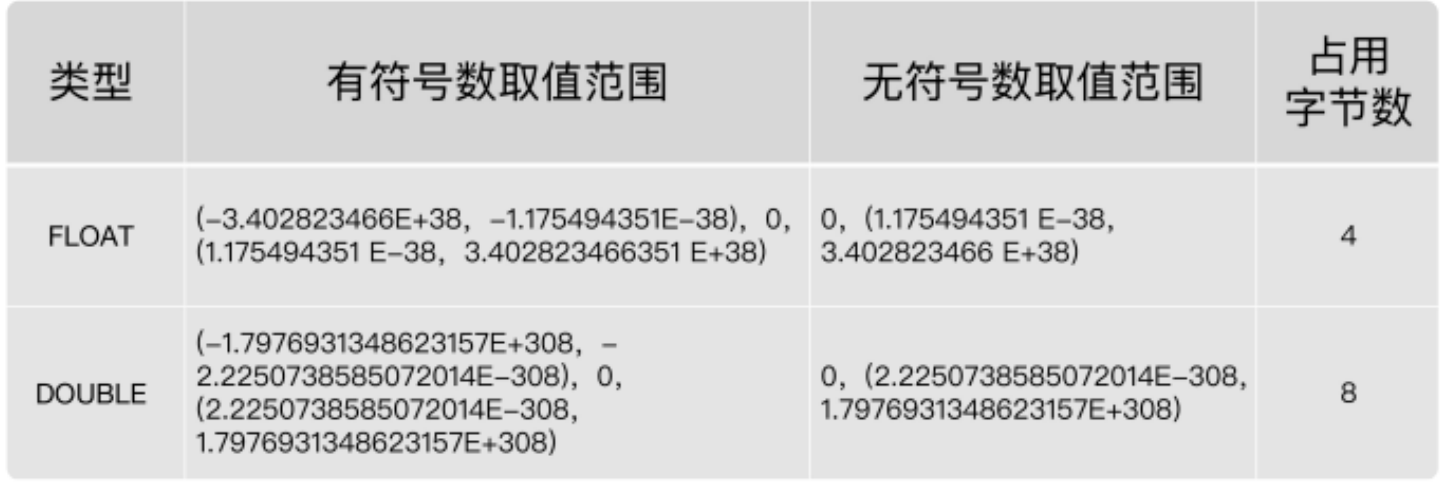
MySQL 存储浮点数的格式为: 符号(S) 、 尾数(M) 和 阶码(E) 。
因此,无论有没有符号,MySQL 的浮点数都会存储表示符号的部分。
浮点数的无符号数取值范围,其实就是有符号数取值范围大于等于零的部分。
在MySQL 8.0中明确不推荐使用:MySQL允许使用 非标准语法 (不推荐使用,数据迁移也许存在问题)
格式:FLOAT(M,D) 或 DOUBLE(M,D) 。
这里,M称为 精度 ,D称为 标度 。(M,D)中 M=整数位+小数 位,D=小数位。 D<=M<=255,0<=D<=30。
例如,定义为FLOAT(5,2)的一个列可以显示为-999.99-999.99。如果超过这个范围会报错。
补充:浮点数是存在精度损失的,因此浮点数是不准确的,所以我们要避免使用“=”来 判断两个数是否相等。
定点数类型
MySQL中的定点数类型只有 DECIMAL 一种类型。
DECIMAL(M,D)的最大取值范围与DOUBLE类型一样,但是有效的数据范围是由M和D决定的。
定点数在MySQL内部是以 字符串 的形式进行存储,因此它是精准的
当DECIMAL类型不指定精度和标度时,其默认为DECIMAL(10,0)。
但是,当数据的精度超出了定点数类型的 精度范围时,则MySQL同样会进行四舍五入处理。
| 数据类型 | 字节数 | 含义 |
|---|---|---|
| DECIMAL(M,D),DEC,NUMERIC | M+2字节 | 有效范围由M和D决定 |
浮点数 与 定点数 的区别:
①浮点数相对于定点数的优点是在长度一定的情况下,浮点类型取值范围大,但是不精准,适用 于需要取值范围大,又可以容忍微小误差的科学计算场景(比如
计算化学、分子建模、流体动 力学等)
②定点数类型取值范围相对小,但是精准,没有误差,适合于对精度要求极高的场景 (比如涉 及金额计算的场景)
位类型(Bit)
BIT类型中存储的是二进制值,类似010110。
BIT类型,如果没有指定(M),默认是1位。
这个1位,表示只能存1位的二进制值。这里(M)是表示二进制的 位数,位数最小值为1,最大值为64。
| 二进制字符串类型 | 长度 | 长度范围 | 占用空间 |
|---|---|---|---|
| BIT(M) | M | 1 <= M <= 64 | 约为(M + 7)/8个字节 |
- 注意:在向BIT类型的字段中插入数据时,一定要确保插入的数据在BIT类型支持的范围内。
- 使用b+0查询数据时,可以直接查询出存储的十进制数据的值。
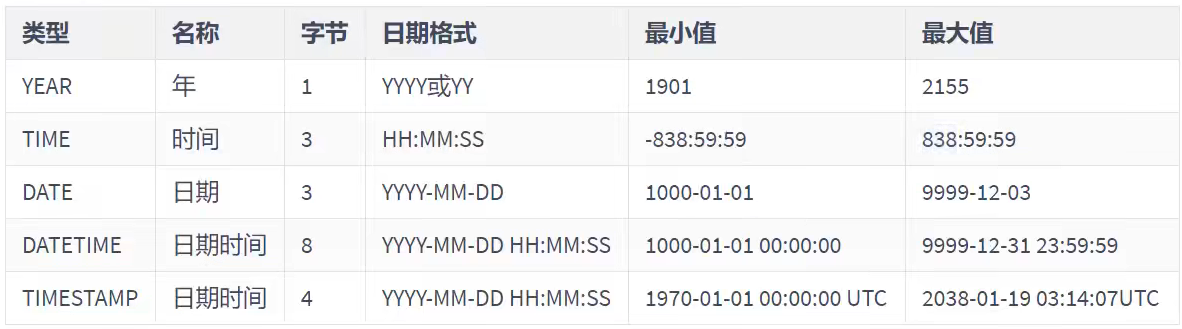
日期和时间类型
- YEAR 类型通常用来表示年
- DATE 类型通常用来表示年、月、日
- TIME 类型通常用来表示时、分、秒
- DATETIME 类型通常用来表示年、月、日、时、分、秒
- TIMESTAMP 类型通常用来表示带时区的年、月、日、时、分、秒
YEAR类型
Year类型所占存储空间最小,只需要 1 个字节的存储空间
在MySQL中YEAR的存储格式:
以4位字符串或数字格式表示YEAR类型,其格式为YYYY,最小值为1901,最大值为2155。
(从MySQL5.5.27开始,2位格式的YEAR已经不推荐使用) 以2位字符串格式表示YEAR类型,最小值为00,最大值为99。
当取值为01到69时,表示2001到2069;
当取值为70到99时,表示1970到1999;
当取值整数的0或00添加的话,那么是0000年;
当取值是日期/字符串的’0’添加的话,是2000年。
DATE类型
DATE类型占用 3个字节 的存储空间
在MySQL中DATE的存储格式: YYYY-MM-DD ,DATE类型表示日期,没有时间部分
- 使用 CURRENT_DATE() 或者 NOW() 函数,会插入当前系统的日期。
TIME类型
TIME类型占用 3个字节 的存储空间
在MySQL中DATE的存储格式:
- ‘ D HH:MM:SS’ 、’ HH:MM:SS ‘、’ HH:MM ‘、’ D HH:MM ‘、’ D HH ‘或’ SS ‘格式
其中D表示天,其最小值为0,最大值为34。
如果使用带有D格式的字符串 插入TIME类型的字段时,D会被转化为小时,计算格式为D*24+HH。
当使用带有冒号并且不带D的字符串 表示时间时,表示当天的时间,比如12:10表示12:10:00,而不是00:12:10。
(不推荐使用)可以使用不带有冒号的 字符串或者数字,格式为’ HHMMSS ‘或者 HHMMSS 。
如果插入一个不合法的字符串或者数字,MySQL在存 储数据时,会将其自动转化为00:00:00进行存储。
比如1210,MySQL会将最右边的两位解析成秒,表示 00:12:10,而不是12:10:00。
使用 CURRENT_TIME() 或者 NOW() ,会插入当前系统的时间。
DATETIME类型
DATETIME类型占用 8个字节 的存储空间
在MySQL中DATETIME的存储格式:
YYYY-MM-DD HH:MM:SS
其中YYYY表示年份,MM表示月 份,DD表示日期,HH表示小时,MM表示分钟,SS表示秒。
以 YYYY-MM-DD HH:MM:SS 格式或者 YYYYMMDDHHMMSS 格式的字符串插入DATETIME类型的字段时,
最小值为1000-01-01 00:00:00,最大值为9999-12-03 23:59:59。
隐式转换:以YYYYMMDDHHMMSS格式的数字插入DATETIME类型的字段时,会被转化为YYYY-MM-DD HH:MM:SS格式。
使用 CURRENT_TIMESTAMP() 和 NOW() ,会插入系统的当前日期和 时间。
TIMESTAMP类型
TIMESTAMP类型占用 4个字节 的存储空间,但取值范围比DATETIME类型要小,底层以毫秒数储存
在MySQL中TIMESTAMP的存储格式:
YYYY-MM-DD HH:MM:SS
存储数据的时候需要对当前时间所在的时区进行转换,查询数据的时候再将时间转换回当前的时区。
因此,使用TIMESTAMP存储的同一个时间值,在不同的时区查询时会显示不同的时间。
TIMESTAMP和DATETIME的区别:
①TIMESTAMP存储空间比较小,表示的日期时间范围也比较小
②底层存储方式不同,TIMESTAMP底层存储的是毫秒值,距离1970-1-1 0:0:0 0毫秒的毫秒值。
③两个日期比较大小或日期计算时,TIMESTAMP更方便、更快。
④TIMESTAMP和时区有关。TIMESTAMP会根据用户的时区不同,显示不同的结果。
⑤DATETIME则只能 反映出插入时当地的时区,其他时区的人查看数据必然会有误差的。
补充:DATETIME 和 TIMESTAMP 的使用频率分析:
用得最多的日期时间类型,就是 DATETIME 。此外,一般存注册时间、商品发布时间等,不建议使用DATETIME存储,
而是使用 时间戳 ,因为 DATETIME虽然直观,但不便于计算。
SELECT UNIX_TIMESTAMP();获取一个时间戳
文本字符串类型
MySQL中,文本字符串总体上分为 CHAR 、 VARCHAR 、 TINYTEXT 、 TEXT 、 MEDIUMTEXT 、 LONGTEXT 、 ENUM 、 SET 等类型。
CHAR 、VARCHAR类型
| 字符串(文本) 类型 | 特点 | 长度 | 长度范围 | 占用的存储空间 |
|---|---|---|---|---|
| CHAR(M) | 固定长度 | M | 0 <= M <= 255 | M个字符 |
| VARCHAR(M) | 可变长度 | M | 0 <= M <= 65535 | (实际长度 + 1) 个字符 |
CHAR类型:
CHAR(M) 类型一般需要预先定义字符串长度。如果不指定(M),则表示长度默认是1个字符。
如果保存时,数据的实际长度比CHAR类型声明的长度小,则会在 右侧填充 空格以达到指定的长度。
当MySQL检索CHAR类型的数据时,CHAR类型的字段会去除尾部的空格。
- 定义CHAR类型字段时,声明的字段长度即为CHAR类型字段所占的存储空间的字节数。
VARCHAR类型:
VARCHAR(M) 定义时, 必须指定 长度M,否则报错。
MySQL4.0版本以下,varchar(20):指的是20字节,如果存放UTF8汉字时,只能存6个(每个汉字3字节) ;
MySQL5.0版本以上,varchar(20):指的是20字符。
检索VARCHAR类型的字段数据时,会保留数据尾部的空格。
VARCHAR类型的字段所占用的存储空间 为字符串实际长度加1个字节。
CHAR 和 VARCHAR的区别:
| 类型 | 特点 | 空间上 | 时间上 | 适用场景 |
|---|---|---|---|---|
| CHAR(M) | 固定长度 | 浪费存储空间 | 效率高 | 存储不大,速度要求高 |
| VARCHAR(M) | 可变长度 | 节省存储空间 | 效率低 | 不适用于char的情况 |
情况1:存储很短的信息。比如门牌号码101,201……这样很短的信息应该用char,因为varchar还要占个 byte用于存储信息长度,本来打算节约存储的,结果得
不偿失。
情况2:固定长度的。比如使用uuid作为主键,那用char应该更合适。因为他固定长度,varchar动态根据 长度的特性就消失了,而且还要占个长度信息。
情况3:十分频繁改变的column。因为varchar每次存储都要有额外的计算,得到长度等工作,如果一个 非常频繁改变的,那就要有很多的精力用于计算,而这些
对于char来说是不需要的。
TEXT文本类型
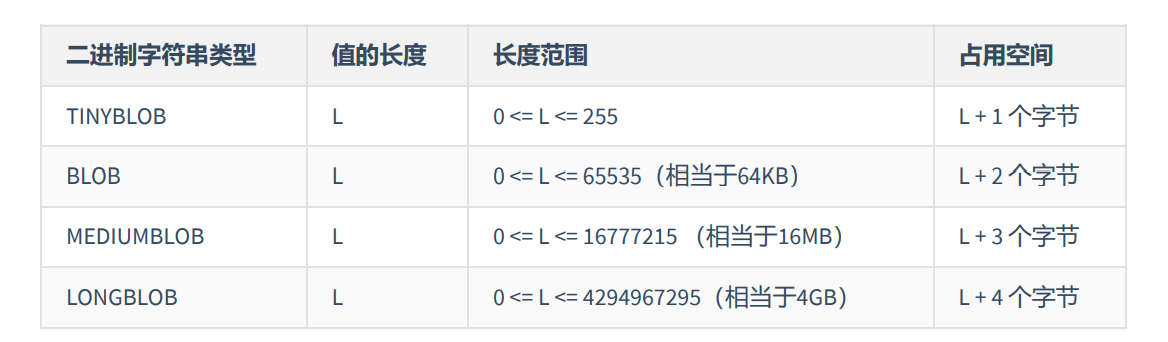
在MySQL中,TEXT用来保存文本类型的字符串,总共包含4种类型,分别为TINYTEXT、TEXT、 MEDIUMTEXT 和 LONGTEXT 类型。
| 文本字符串类型 | 特点 | 长度 | 长度范围 | 占用的存储空间 |
|---|---|---|---|---|
| TINYTEXT | 小文本、可变长度 | L | 0 <= L <= 255 | L + 2 个字符 |
| TEXT | 文本、可变长度 | L | 0 <= L <= 65535 | L + 2 个字符 |
| MEDIUMTEXT | 中等文本、可变长度 | L | 中等文本、可变长度 | L + 3 个字符 |
| LONGTEXT | 大文本、可变长度 | L | 0 <= L<= 4294967295(相当于 4GB) | L + 4 个字符 |
- 由于实际存储的长度不确定,MySQL 不允许 TEXT 类型的字段做主键。在这种情况下只能采用 CHAR(M),或者 VARCHAR(M)。
ENUM枚举类型
ENUM类型也叫作枚举类型,必须从取值范围中添加的元素中多选一,不能一次选多个值。
| 文本字符串类型 | 长度 | 长度范围 | 占用的存储空间 |
|---|---|---|---|
| ENUM | L | 1 <= L <= 65535 | 1或2个字符 |
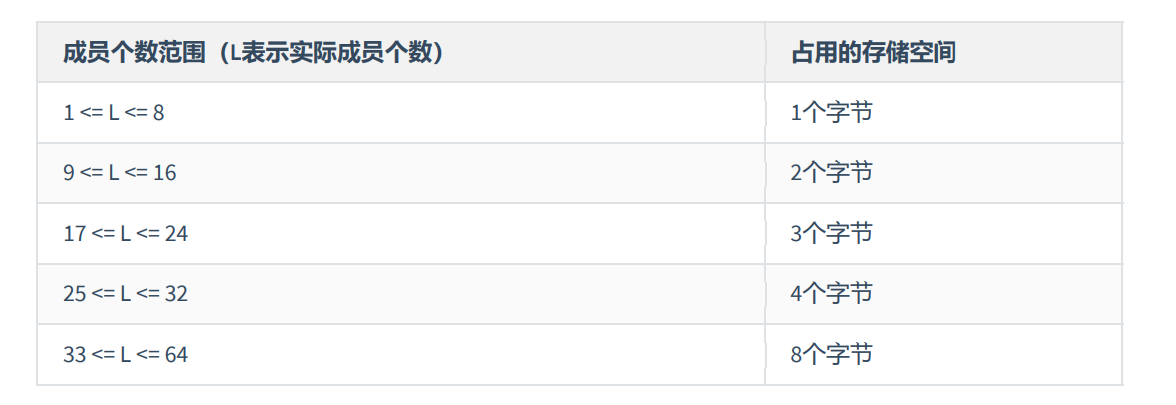
- 当ENUM类型包含1~255个成员时,需要1个字节的存储空间;
- 当ENUM类型包含256~65535个成员时,需要2个字节的存储空间。
- ENUM类型的成员个数的上限为65535个。
1 | #创建表 |
SET类型
可以从取值范围中添加的元素中添加多个,但取值范围中的元素越多,则占用空间越大
- 插入重复的SET类型成员,MySQL会自动删除重复的成员
1 | #创建表 |
二进制字符串类型
使用频率较低,了解一下
MySQL中支持的二进制字符串类型主要包括BINARY、VARBINARY、TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB类型。
BINARY 、VARBINARY类型
BINARY和VARBINARY,只是它们存储的是二进制字符串。
BINARY 、VARBINARY类型的存储类似于CHAR和VARCHAR

BLOB类型
MySQL中的BLOB类型包括TINYBLOB、BLOB、MEDIUMBLOB和LONGBLOB 4种类型,
它们可容纳值的最大 长度不同。可以存储一个二进制的大对象,比如 图片 、 音频 和 视频 等。
TEXT和BLOB两者都需要注意的事项:
①在针对以BLOB和TEXT类型的字段数据进行大量的删除和更新的操作之后,在数据表上会留下很多碎片,造成数据库的”空洞“,会对数据库的检索效率造成较大
的影响,可以使用指令 OPTIMIZE TABLE 解决这些空洞问题
②对数据量很大的文本字段进行模糊查询时,MySQL 提供了 前缀索引 ,但不宜不添加任何条件的情况下检索大量的数据,无目的的检索会让数据库于I/O的交互
次数增加,反而形成负优化。
③针对上述的第一种情况,需要对数据量大的文本数据进行操作时,可以考虑将这些数据移动到另一张数据表中,主表不会因为副表的删除、更新数据的影响产生
过多的数据”空洞”,有利于优化查询速度
JSON类型
JSON 可以将 JavaScript 对象中表示的一组数据转换为字符串,然后就可以在网络或者程序之间轻 松地传递这个字符串,并在需要的时候将它还原为各编程语言所支持的数据格式。
1 | #创建json表 |
通过“->”和“->>”符号,从JSON字段中正确查询出了指定的JSON数据的值。
空间类型
使用较少,略
约束
数据完整性是指数据的精确性和可靠性。
数据库以约束的方式对表数据进行额外的条件限制,以此确保数据的完整性,数据的完整性可以从四个方面考虑:
①实体完整性。如:同张表不能出现完全相同的记录
②域完整性。如:年龄范围0-120
③引用完整性。如:员工所在的部门,在部门表中一定会存在此部门
④用户自定义完整性。如:用户名唯一、用户名不为空。
约束的分类
约束的字段个数
单列约束 :每个约束只约束一列
多列约束:每个约束可约束多列数据
约束的作用范围
列级约束:将此约束声明在对应的字段的后面
表级约束:在表中所有字段声明完,在所有字段后面声明的约束
约束的作用
①not null (非空约束)
②unique (唯一性约束)
③primary key (主键约束)
④foreign key (外键约束)
⑤check (检查约束)
⑥defalut (默认值约束)
添加约束的方式
CREATE TABLE时添加约束
ALTER TABLE时增加约束、删除约束
- 查看表中的约束
1 | #information_schema数据库名(系统库) |
非空约束*
作用:限定某个字段/列不能为空
非空约束只能用列级约束,不能使用表级约束
关键字:NOT NULL
在创建表的时候添加约束
CREATE TABLE 表名称(
字段名 数据类型,
字段名 数据类型 NOT NULL,
字段名 数据类型 NOT NULL );
建表后通过MODIFY + 列级约束的方式 增加约束
alter table 表名称
modify 字段名 数据类型 not null;
删除非空约束
alter table 表名称
modify 字段名 数据类型 NULL;
alter table 表名称
modify 字段名 数据类型;
1 | #在创建表的时候添加约束 |
唯一性约束*
作用:限定某个字段/列不能重复
关键字:UNIQUE
创建表的时候添加约束
①列级约束:
create table 表名称(
字段名 数据类型,
字段名 数据类型 unique,
字段名 数据类型 );
②表级约束:
create table 表名称(
字段名 数据类型,
字段名 数据类型,
字段名 数据类型,
[constraint 约束名] unique key(字段名));
建表后
①通过ADD + 表级约束的方式 增加约束
alter table 表名称
add constraint 约束名 unique key(字段列表);
②通过MODIFY + 列级约束的方式 增加约束
alter table 表名称
modify 字段名 字段类型 unique;
复合唯一性约束:
create table 表名称(
字段名 数据类型,
字段名 数据类型,
字段名 数据类型,
unique key(字段列表));
表示用户名和密码组合不能重复,即表中的两个数据的用户名和密码不能完全一致
删除唯一约束
ALTER TABLE 数据表名
DROP INDEX 创建唯一约束时所起的名字;
删除唯一约束即通过删除唯一索引,删除时指定的唯一索引名为 创建唯一约束时所起的名字
创建唯一约束时所起的名字(若是单列,默认和列名相同;若是组合列,默认是字段列表中的第一个字段的名字)
1 | #唯一性约束 |
主键约束*
作用:用来唯一标识表的一行记录,一个表中最多只能由一个主键约束
主键约束相当于唯一约束 + 非空约束的组合,即不允许列重复,也不能出现空值
关键字:primary key
创建表时添加主键约束
①表级约束:
create table 表名称(
字段名 数据类型,
字段名 数据类型,
字段名 数据类型,
[constraint 约束名] primary key(字段名) );
②列级约束
create table 表名称(
字段名 数据类型 primary key,
字段名 数据类型,
字段名 数据类型)
建表后添加主键约束
①使用MODIFY + 列级约束在CREATE TABLE 之后添加主键约束
ALTER TABLE 表名称MODIFY 字段名 数据类型 PRIMARY KEY;
②使用ADD + 表级约束在CREATE TABLE 之后添加主键约束
ALTER TABLE 表名称
ADD PRIMARY KEY(字段列表)
复合主键约束
create table 表名称(
字段名 数据类型,
字段名 数据类型,
字段名 数据类型,
primary key(字段名1,字段名2) );
多列组合的复合主键约束,其中任何列的值都不允许为null,且不能完全一致和重复
删除主键约束(不建议删除,破坏了数据的特征)
alter table 表名称
drop primary key;
补充:删除表的主键约束后由其影响的不能为空的性质依旧存在
1 | #主键约束 |
自增列
作用:某个字段的值自增
关键字:AUTO_INCREMENT
自增列的特定和要求:
- 一个表最多只能有一个自增长列
- 当需要产生唯一标识符或顺序值时,可设置自增长
- 自增长列约束的列必须是键列(主键列,唯一键列)
- 自增约束的列的数据类型必须是整数类型
- 如果自增列指定了 0 和 null,会在当前最大值的基础上自增;如果自增列手动指定了具体值,直接 赋值为具体值。
使用MODIFY + 列级约束在CREATE TABLE 之后添加自增列
alter table 表名称
modify 字段名 数据类型 auto_increment;
删除自增约束
alter table 表名称
modify 字段名 数据类型;
1 | #创建表时添加自增列 |
外键约束
不建议在数据库层面使用,可以了解一下
原因是:在 MySQL 里,外键约束是有成本的,因为外键约束的系统开销而变得非常慢
而在应用层面也可以起到限制作用,来实现外键约束的功能,确保数据的一致性。
作用:限定某个表的字段的引用完整性
关键字:FOREIGN KEY
主表和从表
主表(父表):被引用的表,被参考的表
从表(子表):引用其他的表,参考其他的表
外键约束的特点:
①在创建外键约束时,如果不给外键约束命名,默认名不是列名,
而是自动产生一个外键名(例如 student_ibfk_1;),也可以指定外键约束名。
②在“从表”中指定外键约束,并且一个表可以建立多个外键约束
③在对主表进行增删改的操作之前要解除从表对主表的引用
④从表的外键列,必须引用/参考主表的主键或唯一约束的列
约束等级
Cascade方式 :对主表的update/delete操作,会同步到从表中。
Set null方式 :对主表的update/delete操作,不会同步到从表中,从表中的数据被设为null
No action方式 :如果主表被其他从表引用,则在解除引用之前不允许主表进行任何update/delete操作。
Restrict方式 :同no action, 都是立即检查外键约束 Set default方式,不允许任何操作在解除引用之前
如果没有指定等级,就相当于Restrict方式
对于外键约束,最好是采用: ON UPDATE CASCADE ON DELETE RESTRICT 的方式。
1 | #在建表时添加外键约束 |
检查约束
作用:检查某个字段的值是否符合xx的要求,一般指的是值的范围
关键字:check
MySQL5.7不支持check约束,而在8.0才支持
1 | CREATE TABLE test( |
默认值约束*
作用:给某个字段/某列指定默认值,一旦设置默认值,在插入数据时,如果此字段没有显式赋值,则赋值为默认值。
关键字:DEFAULT
建立表时
create table 表名称(
字段名 数据类型 primary key,
字段名 数据类型 unique key not null,
字段名 数据类型 unique key,
字段名 数据类型 not null default 默认值, );
在建表后添加使用MODIFY + 列级约束在CREATE TABLE 之后添加默认值约束
alter table 表名称
modify 字段名 数据类型 default 默认值;
删除默认值约束
alter table 表名称
modify 字段名 数据类型 default 默认值 not null;
为什么建表时,加 not null default ‘’ 或 default 0
答:不想让表中出现null值。
带AUTO_INCREMENT约束的字段值是从1开始的吗?
答:不是,如果显式指定字段的值,则从此字段值开始自增
为什么不想要 null 的值?
答:不好比较。任何值与null做运算都是null;且效率较低,影响索引效果
每个表都可以任意选择存储引擎?
答:不是。外键约束(FOREIGN KEY)不能跨引擎使用。要求外键和主键需要使用一致的存储引擎
1 | CREATE TABLE test1( |
数据库的相关对象
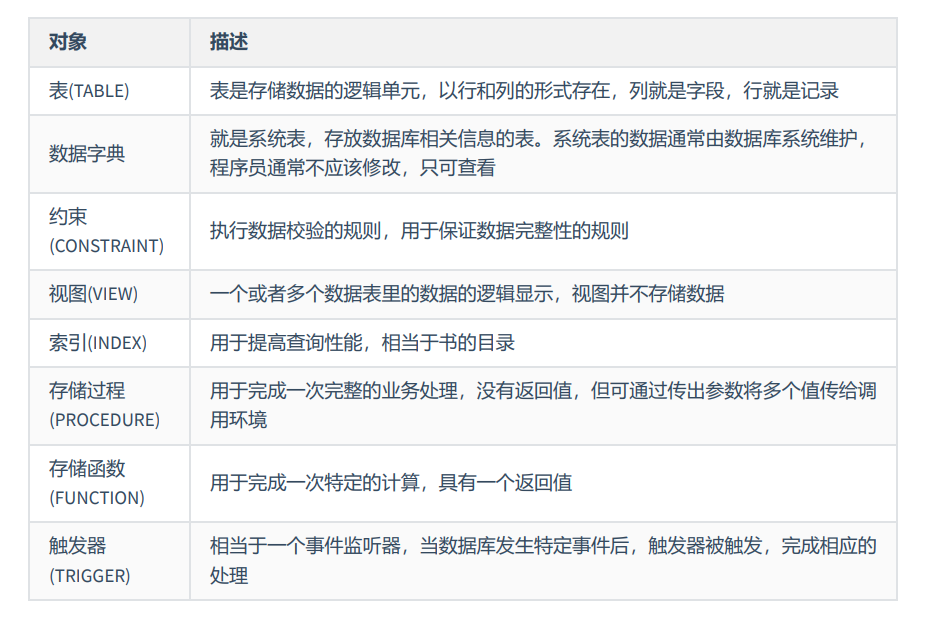
视图
视图从本质上来说可以理解为是个已经存储起来的SELECT语句
视图可以看做一个虚拟表,其本身是不存储任何数据的
视图创建所涉及的表称为 基表
针对视图进行的DML增删改的操作,也会修改对应的基表数据。反过来,对基表的操作也会影响视图的显示内容
视图其本身的创建和删除对基表中的数据没有影响
视图的优点:①简化查询,提高索引效率;②控制数据访问者的权限大小
视图的应用场景:小型项目的表较少不推荐使用视图,而针对大型项目,表较多数据比较复杂则可以考虑使用视图
创建视图
完整版:
CREATE [OR REPLACE]
[ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
VIEW 视图名称 [(字段列表)]
AS 查询语句
[WITH [CASCADED|LOCAL] CHECK OPTION]
1 | #单表视图 |
查看视图
1 | #查看数据库的表和视图 |
更新视图的数据
1 | SELECT * FROM v_emp; |
删除视图
格式:DROP VIEW IF EXISTS 视图名称
- 基于视图a、视图b建立的视图,在视图a、b删除后,视图c也会失效,除非手动修改或删除
视图的优缺点
优点:
①操作简单,操作人员不需要关注数据的底层结构等等
②减少数据冗余,其是利用基表生成的,没有实际的数据,其数据都源于基表
③数据安全,可以限制数据访问者的权限大小
④适应灵活多变的需求,
⑤能够分解复杂的查询逻辑,可以将复杂的查询保存下来。
缺点:维护成本过高,因此小项目不推荐使用,大项目则可以考虑
存储过程 与 存储函数
概念:存储过程(Stored Procedure),将一组经过 预先编译 的 SQL语句的封装。
执行过程:存储过程预先存储在 MySQL 服务器上,需要执行的时候,客户端只需要向服务器端发出调用 存储过程的命令,
服务器端就可以把预先存储好的这一系列 SQL 语句全部执行。
与视图、函数的对比:
视图是基于基表而成虚拟表,本身以提供查询为主,增删改操作较少,而存储过程是直接操作底层数据表的SQL语句
存储过程 与 存储函数的区别在乎存储过程没有返回值,存储函数有返回值
存储过程的创建、调用
格式:
DELIMITER $
CREATE PROCEDURE 存储过程名(IN|OUT|INOUT 参数名 参数类型,…)
[characteristics …]
BEGIN 存储过程体
END $
DELIMITER ;
1 | #创建存储过程 |
储存函数的使用
格式:
CREATE FUNCTION 函数名(参数名 参数类型,…)
RETURNS 返回值类型
[characteristics …]
BEGIN 函数体 #函数体中肯定有 RETURN 语句
END
1 | #1.创建存储函数,名称为email_by_name(),参数定义为空,该函数查询Abel的email,并返回,数据类型为字符串型。 |
存储过程和存储函数的对比
| 关键字 | 调用语法 | 返回值 | 应用场景 | |
|---|---|---|---|---|
| 存储过程 | PROCEDURE | CALL 存储过程() | 理解为有0个或 多个 | 一般用于更新 |
| 存储函数 | FUNCTION | SELECT 函数 () | 只能是一个 | 一般用于查询结果为一个值并返回时 |
- 存储函数可以放在查询语句中使用,存储过程不行。
- 但存储过程的功能比存储函数强大
存储过程与存储函数的查看、修改、删除
查看
①SHOW CREATE {PROCEDURE | FUNCTION} 存储过程名或函数名
②SHOW {PROCEDURE | FUNCTION} STATUS [LIKE ‘pattern’]
③SELECT * FROM information_schema.Routines
WHERE ROUTINE_NAME=’存储过程或函数的名’
[AND ROUTINE_TYPE = {‘PROCEDURE|FUNCTION’}];
修改
修改的只是函数的特性,不能修改存储过程或者存储功能,
使用ALTER语句characteristic指定存储过程或函数的特性,
ALTER {PROCEDURE | FUNCTION} 存储过程或函数的名 [characteristic …]
删除
DROP {PROCEDURE | FUNCTION} [IF EXISTS] 存储过程或函数的名称
存储过程的优缺点
优点:
①存储过程可以一次编译多次使用
②可以减少开发工作量
③存储过程的安全性强
④可以减少网络传输量。
⑤可以减少网络传输量。
缺点:
①可移植性差
②调试困难
③存储过程的版本管理很困难。
④它不适合高并发的场景
变量
在MySQL中,变量分为 系统变量 和 用户自定义变量
系统变量
系统变量又分为 全局(global)系统变量 和 会话系统变量(session),以@@开头
全局系统变量:其软件内置的变量(俗称写死在代码中的)和配置文件中的变量。
会话系统变量:大部分来自于全局变量的复制,当连接断开时这些会话变量全部消失,重新连接时会从全局变量中重新复制一份。
针对系统变量没有显式指定,则默认为会话系统变量
查看系统变量
查看所有全局变量
SHOW GLOBAL VARIABLES;
查看所有会话变量
SHOW SESSION VARIABLES; 或 SHOW VARIABLES;
查看满足条件的部分系统变量。
SHOW GLOBAL VARIABLES LIKE ‘%标识符%’;
查看满足条件的部分会话变量
SHOW SESSION VARIABLES LIKE ‘%标识符%’;
查看指定系统变量
查看指定的系统变量的值
SELECT @@global.变量名;
查看指定的会话变量的值
SELECT @@session.变量名;
SELECT @@变量名 此方式是默认先在会话系统变量中查找,找不到才到全局系统变量中查找
修改系统变量的值
①全局系统变量
SET @@global.变量名=变量值;
SET GLOBAL 变量名=变量值;
针对当前的数据库是有效,一旦数据库重启就失效了
②会话系统变量
SET @@session.变量名=变量值;
SET SESSION 变量名=变量值;
针对当前会话是有效的,一旦结束会话,重新建立新的会话也就失效了
用户变量
用户变量又分为 会话用户变量 和 局部变量
会话用户变量:作用域和会话变量一样,只对 当前连接 会话有效。
局部变量:只在 BEGIN 和 END 语句块中有效。局部变量只能在 存储过程和函数 中使用。
- 会话用户变量的定义
SET @用户变量 = 值;
SET @用户变量 := 值;
SELECT @用户变量 := 表达式 [FROM 等子句];
SELECT 表达式 INTO @用户变量 [FROM 等子句];
查看会话用户变量的值
SELECT @用户变量名
局部变量:
①**局部变量必须使用declare声明 **
②声明并使用在begin….end 中(使用在存储过程和存储函数里面)
③declare的方式声明的局部变量必须声明在begin的首行位置
格式:
1 | BEGIN |
会话用户变量 和 局部变量的区别
作用域 定义位置 语法 会话用户变量 当前会话 会话的任何地方 加@符号,不用指定类型 局部变量 定义它的BEGIN END中 BEGIN END的第一句话 一般不用加@,需要指定类型
定义条件与处理程序
定义条件 是事先定义程序执行过程中可能遇到的问题,
处理程序 定义了在遇到问题时应当采取的处理方 式,并且保证存储过程或函数在遇到警告或错误时能继续执行。
- 说明:定义条件和处理程序在存储过程、存储函数中都是支持的。
定义条件
定义条件即给MySQL中的错误码命名,将一个 错误名字 和 指定的 错误条件 关联起来
这样就能在处理程序的 DECLARE HANDLER 语句中使用。
错误码的说明:MySQL_error_code 和 **sqlstate_value **都可以表示MySQL的错误。
MySQL_error_code是数值类型错误代码。 sqlstate_value是长度为5的字符串类型错误代码。
例如,在ERROR 1418 (HY000)中,1418是MySQL_error_code,’HY000’是sqlstate_value。
格式:
DECLARE 错误名称 CONDITION FOR 错误码(或错误条件)
1 | #定义"ERROR 1148(42000)"错误,名称为command_not_allowed。 |
处理程序
处理程序可以为SQL执行过程中发生的某种类型的错误进行特点的处理
格式:
DECLARE 处理方式 HANDLER FOR 错误类型 处理语句
- 处理语句必须在sql语句执行之前声明

1 | #方法1:捕获sqlstate_value |
流程控制
IF结构
- IF语句的语法结构:
IF 表达式1 THEN 操作1
[ELSEIF 表达式2 THEN 操作2]……
[ELSE 操作N]
END IF
1 | #声明存储过程“update_salary_by_eid1”,定义IN参数emp_id,输入员工编号。判断该员工 |
CASE结构
- CASE语句的语法结构1:
\情况一:类似于switch
CASE 表达式 WHEN 值1 THEN 结果1或语句1(如果是语句,需要加分号)
WHEN 值2 THEN 结果2或语句2(如果是语句,需要加分号)
…
ELSE 结果n或语句n(如果是语句,需要加分号)
END [case](如果是放在begin end中需要加上case,如果放在select后面不需要)
- CASE语句的语法结构2:
情况二:类似于多重if
CASE WHEN 条件1 THEN 结果1或语句1(如果是语句,需要加分号)
WHEN 条件2 THEN 结果2或语句2(如果是语句,需要加分号)
…
ELSE 结果n或语句n(如果是语句,需要加分号)
END [case](如果是放在begin end中需要加上case,如果放在select后面不需要)
1 | #声明存储过程“update_salary_by_eid4”,定义IN参数emp_id,输入员工编号。判断该员工 |
循环结构
LOOP结构
LOOP循环语句用来重复执行某些语句。LOOP内的语句一直重复执行直到循环被退出(使用LEAVE语句),跳出循环过程。
格式:loop_label表示LOOP语句的标注名称,可以选择省略
[ loop_label: ] LOOP
循环执行的语句
END LOOP[ loop_label ];
1 | #当市场环境变好时,公司为了奖励大家,决定给大家涨工资。 |
WHILE结构
WHILE 类似于Java中的while一样
WHILE语句创建一个带条件判断的循环过程。
WHILE在执行语句执行时,会对指定的表达式进行判断,循环体被执行到直至循环条件为假 就会退出循环
格式: while_label 表示WHILE语句的标注名称,可以选择省略,
[ while_label :] WHILE 循环条件 DO
循环体
END WHILE [ while_label]
1 | #市场环境不好时,公司为了渡过难关,决定暂时降低大家的薪资。 |
REPEAT结构
REPEAT类似于Java中do - while,不管结果如何首先执行一次
REPEAT语句创建一个带条件判断的循环过程。
REPEAT 循环首先会执行一次循环,然后在 UNTIL 中进行表达式的判断,
循环体内的语句会被重复,直至 循环条件为真就退出。
格式:repeat_label为REPEAT语句的标注名称,该参数可以省略;
[ repeat_label : ] REPEAT
循环体
UNTIL 结束循环的条件表达式
END REPEAT [ repeat_label ]
1 | #当市场环境变好时,公司为了奖励大家,决定给大家涨工资。 |
前三种循环的异同
三种循环都可以省略名称,但在循环中添加了循环控制条件(如LEVE 或 ITERATE)则必须要添加名称
LOOP:一般先用于简单的“死循环”,通常需要配合LEAVE使用
WHILE:先判断后运行
REPEAT:先执行后判断,必定先执行一次。
WHILE 和 REPEAT的区别类似于Java中的while和do - while的循环区别
LEVEL的使用
类似与java中的break,结束循环
格式:LEAVE 标记名
1 | #:创建存储过程 “leave_begin()”,声明INT类型的IN参数num。给BEGIN...END加标记名,并在 |
ITERATE的使用
类似与java中的continue,跳过本次循环
格式:ITERATE label
- label参数表示循环的标志。ITERATE语句必须跟在循环标志前面。
1 | #当n < 10 跳出此次循环; n > 15 结束循环 |
游标
游标提供了一种灵活的操作方式,能够对结果集中的每一条记录进行定位,并对指向的记录中的数据进行操作。
游标充当了 指针的作用 ,可以通过操作游标来对数据行进行操作。
使用游标的步骤
- 声明游标
语法格式:DECLARE 游标名 CURSOR FOR 具体的查询语句;
- 打开游标
语法格式:OPEN 游标名
- 使用游标
语法格式:FETCH 游标名 INTO var_name [, var_name] …
- 游标的查询结果集中的字段数,必须跟上方表中查询返回的字段数一致
- 关闭游标
语法格式:CLOSE 游标名
游标会占用系统资源,因此必须关闭,否则会保持到存储过程结束
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35#创建存储过程“get_count_by_limit_total_salary()”,声明IN参数 limit_total_salary,DOUBLE类型;
#声明OUT参数total_count,INT类型。函数的功能可以实现累加薪资最高的几个员工的薪资值,
#直到薪资总和达到limit_total_salary参数的值,返回累加的人数给total_count。
DELIMITER $
CREATE PROCEDURE get_count_by_limit_total_salary(IN limit_total_salary DOUBLE,OUT total_count INT)
BEGIN
#定义局部变量
DECLARE n INT DEFAULT 0;#记录累加的次数
DECLARE emp_sal DOUBLE;#记录某一个员工的工资
DECLARE sum_sal DOUBLE DEFAULT 0.0;#记录累加的工资总和
#定义游标
DECLARE emp_cursor CURSOR FOR SELECT salary FROM emp ORDER BY salary DESC;
#打开游标
OPEN emp_cursor;
REPEAT
#使用游标
FETCH emp_cursor INTO emp_sal;#游标的查询结果集中的字段数,必须跟上方表中查询返回的字段数一致
SET sum_sal = sum_sal + emp_sal;
SET n = n + 1;
UNTIL sum_sal >= limit_total_salary
END REPEAT;
SET total_count = n;
#关闭游标
CLOSE emp_cursor;
END $
DELIMITER ;
CALL get_count_by_limit_total_salary(200000,@total_count);
SELECT @total_count;
触发器
举个例子:可以创建一个触发器,让商品信息数据的插入操作自动触发库存数 据的插入操作。
触发器是由 事件来触发 某个操作,这些事件包括 INSERT 、 UPDATE 、 DELETE 事件。
所谓事件就是指 用户的动作或者触发某项行为。
触发器的创建
语法结构:
CREATE TRIGGER 触发器名称
{BEFORE|AFTER} {INSERT|UPDATE|DELETE} ON 表名
FOR EACH ROW
触发器执行的语句块;
1 | #定义触发器“salary_check_trigger”,基于员工表“employees”的INSERT事件, |
查看、删除触发器
查看触发器
①SHOW TRIGGERS\G
②SHOW CREATE TRIGGER 触发器名称
③SELECT * FROM information_schema.TRIGGERS;
删除触发器
DROP TRIGGER IF EXISTS 触发器名称;
触发器的优缺点
优点:
①触发器可以确保数据的完整性。因为会同步更新修改或删除的数据
②触发器可以帮助我们记录操作日志。任何操作之前都被记录
③触发器还可以用在操作数据前,对数据进行合法性检查。
缺点:
①触发器最大的一个问题就是可读性差。
②相关数据的变更,可能会导致触发器出错。
注意点:
如果在子表中定义了外键约束,并且外键指定了ON UPDATE/DELETE CASCADE/SET NULL子句,
此时修改父表被引用的键值或删除父表被引用的记录行时,也会引起子表的修改和删除操作,
此时基于子表的UPDATE和DELETE语句定义的触发器并不会被激活。
MySQL8.0 新特性
窗口函数分为了 静态窗口函数 和 动态窗口函数
窗口函数
语法格式:
实际上PARTITION BY是可选择的
①函数 OVER ([PARTITION BY 字段名 ORDER BY 字段名 ASC | DESC])
②**函数 OVER 窗口名 … WINDOW 窗口名 AS ([PARTITION BY 字段名 ORDER BY 字段名 ASC | DESC]) **

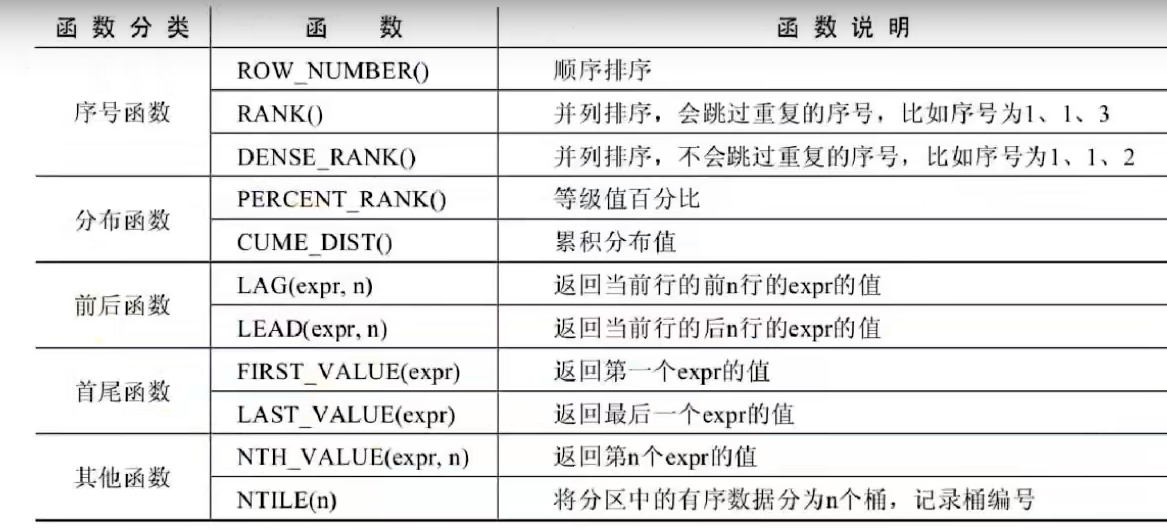
序号函数
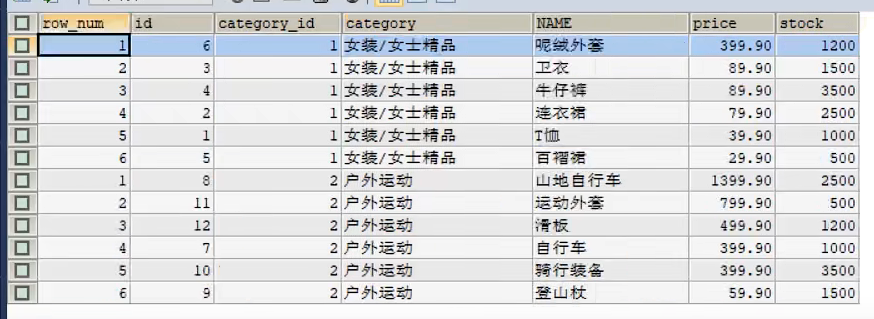
ROW_NUMBER():生成一个呈现分类后序号的列
1 | #查询goods数据表中每个商品分类下价格降序排列的各个商品信息 |
————其他函数用法在此不做说明,
公用表表达式
公共表表达式(Common Table Expressions)可以理解为是一个命名的 临时结果集,作用范围是在当前语句中
也可以把它看作一个支持复用的子查询,但与子查询还是不太一样,cte可以引用别的cte,子查询不能引用别的子查询
其中又分为了 普通公用表表达式 和 递归公用表表达式
普通公用表表达式
语句结构:
WITH CTE名称
AS (子查询)
SELECT| DELETE | UPDATE 语句;
1 | WITH cte_emp |
递归公用表表达式
实际就是自己调用自己
语句结构:
WITHRECURSIVE
CTE名称 AS (子查询)
SELECT| DELETE | UPDATE 语句;
 wechat
wechat alipay
alipay




